While writing this question, I managed to find an explaination. But as it seems a tricky point, I will post it and answer it anyway. Feel free to complement.
I have what appears to me an inconsistent behaviour of pyspark, but as I am quite new to it I may miss something... All my steps are run in an Azure Databricks notebook, and the data is from a parquet file hosted in Azure Datalake Gen. 2.
I want to simply filter the NULL records from a spark dataframe, created by reading a parquet file, with the following steps:

Filtering on the phone column just works fine:

We can see that at least some contact_tech_id values are also missing. But when filtering on this specific column, an empty dataframe is retrieved...

Is there any explaination on why this could happen, or what I should look for?
CodePudding user response:
The reason why filtering on contact_tech_id Null values was unsuccessful is because what appears as null in this column in the notebook output is in fact a NaNvalue ("Not a Number", see 
CodePudding user response:
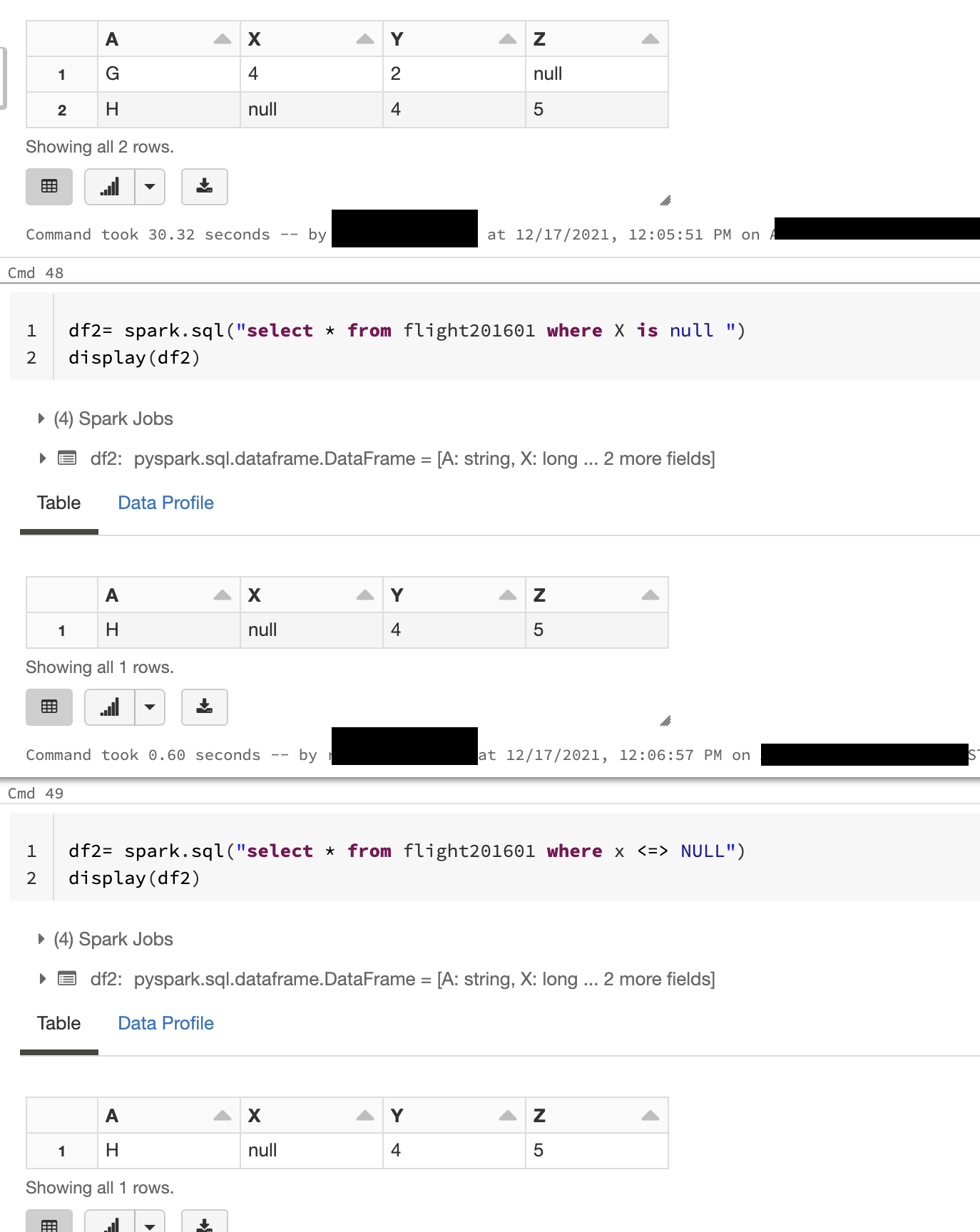
In order to compare the NULL values for equality, Spark provides a null-safe equal operator (<=>), which returns False when one of the operand is NULL and returns True when both the operands are NULL. Instead of using is null always recommend (<=>) operator.
Apache Spark supports the standard comparison operators such as >, >=, =, < and <=. The result of these operators is unknown or NULL when one of the operands or both the operands are unknown or NULL. In order to compare the NULL values for equality, Spark provides a null-safe equal operator (<=>), which returns False when one of the operand is NULL and returns True when both the operands are NULL. You can ref