I have a 3 node HA cluster in a CentOS 8 VM. I am using ZK 3.7.0 and Hadoop 3.3.1. In my cluster I have 2 namenodes, node1 is the active namenode and node2 is the standby namenode in case that node1 falls. The other node is the datanode I just start all with the command
start-dfs.sh
In node1 I had the following processes running: NameNode, Jps, QuorumPeerMain and JournalNode In node2 I had the following processes running: NameNode, Jps, QuorumPeerMain, JournalNode and DataNode.
My hdfs-site.xml configuration is the following:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/datos/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/datos/datanode</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ha-cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.ha-cluster</name>
<value>nodo1,nodo2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-cluster.nodo1</name>
<value>nodo1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-cluster.nodo2</name>
<value>nodo2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ha-cluster.nodo1</name>
<value>nodo1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.ha-cluster.nodo2</name>
<value>nodo2:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://nodo3:8485;nodo2:8485;nodo1:8485/ha-cluster</value>
</property>
The problem is that since the node2 is the standby namenode I didn't want it to have the DataNode process running, so I killed it. I used the command kill -9 (I know it's not the best way, I should have used hdfs --daemon stop datanode).
Then I entered the hadoop website to check how many datanodes I had. In the node1 (the active namenode) Hadoop website, in the datanode part I only had 1 datanode, node3.
The problem is that in the Hadoop website of the node2 (the standby namenode) was like this:
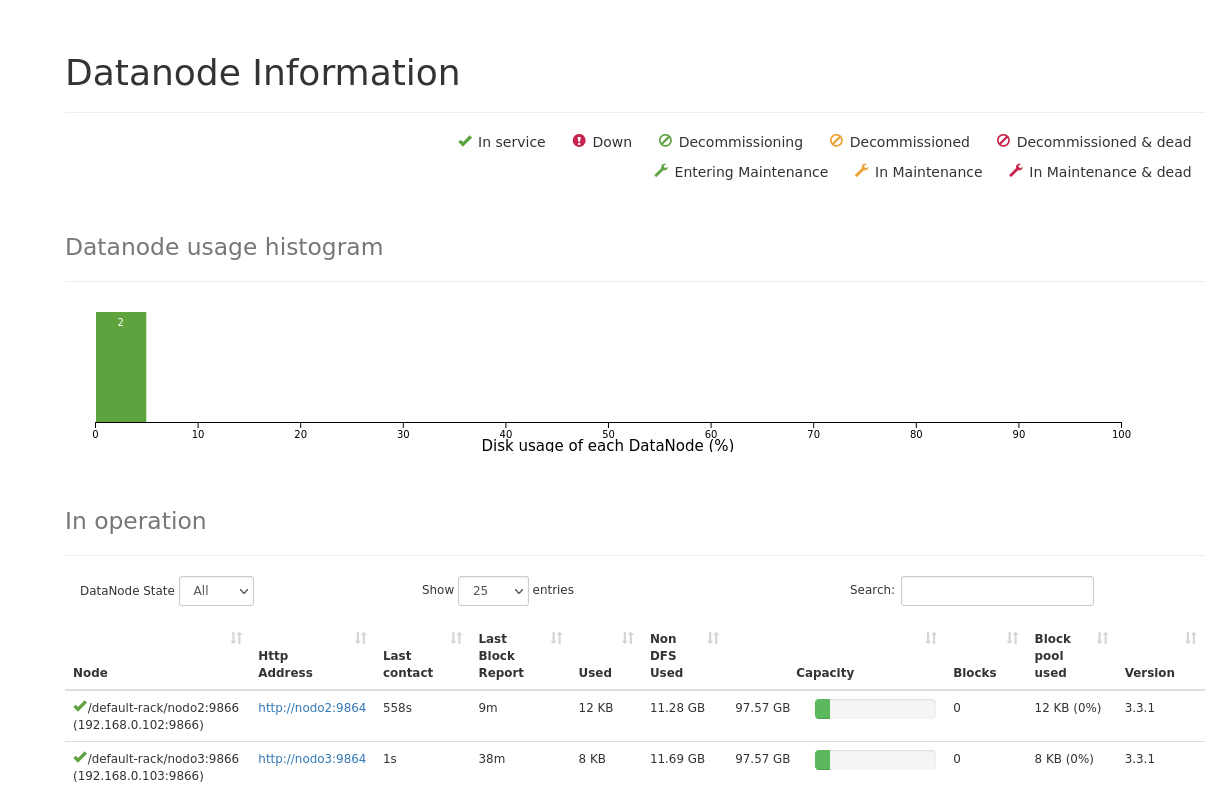
In case u can't see the image:
default-rack/nodo2:9866 (192.168.0.102:9866) http://nodo2:9864 558s
/default-rack/nodo3:9866 (192.168.0.103:9866) http://nodo3:9864 1s
The node2 datanode hasn't been alive for 558s and it doesn't take the node as dead. Does anybody know why does this happen??
CodePudding user response:
in your hdfs-site.xml check values for:
dfs.heartbeat.interval (Determines datanode heartbeat interval in seconds.)
dfs.namenode.heartbeat.recheck-interval (This time decides the interval to check for expired datanodes. With this value and dfs.heartbeat.interval, the interval of deciding the datanode is stale or not is also calculated. The unit of this configuration is millisecond.)
check here for defaults and more info: https://hadoop.apache.org/docs/r2.7.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
There is a formula to determine when a node is dead:
2 * dfs.namenode.heartbeat.recheck-interval 10 * (1000 * dfs.heartbeat.interval)
means:
2 * 300000 10 * 3000 = 630000 milliseconds = 10 minutes 30 seconds or **630 seconds**.
source: Hadoop 2.x Administration Cookbook (Packt) - Configuring Datanode heartbeat:
Datanode Removal time = (2 x dfs.namenode.heartbeat.recheck-interval ) (10 X dfs.heartbeat.interval)