Why is using a numbers table so much faster than using a recursive CTE to generate them on the fly?
On my machine, given a table numbers with a single column n (primary key) containing the numbers from 1 to 100000, the following query:
select n from numbers;
Takes around 400 ms to finish.
Using a recursive CTE to generate the numbers 1 to 100000:
with u as (
select 1 as n
union all
select n 1
from u
where n < 100000
)
select n
from u
option(maxrecursion 0);
Takes about 900ms to finish, both on SQL Server 2019.
My question is, why is the second option so much slower than the first one? Isn't the first one fetching results from disk, and should therefore be slower?
Otherwise, is there any way to make the CTE run faster? Because it seems to me it's a more elegant solution than storing a list of numbers in a database.
CodePudding user response:
The recursive CTE is a CPU expensive operation because SQL Server "loops" over reach row. A materialized numbers table or set-based CTE will perform much faster. Note the CPU and elapsed times reported with SET STATISTICS TIME ON on my workstation (YMMV).
Numbers table:
SELECT * FROM dbo.numbers;
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 231 ms.
Recursive CTE:
with u as (
select 1 as n
union all
select n 1
from u
where n < 100000
)
select n
from u
option(maxrecursion 0);
SQL Server Execution Times:
CPU time = 375 ms, elapsed time = 529 ms.
Set-based CTE:
WITH
t10 AS (SELECT n FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) t(n))
,t1k AS (SELECT 0 AS n FROM t10 AS a CROSS JOIN t10 AS b CROSS JOIN t10 AS c)
,t100k AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 0)) AS n FROM t1k AS a CROSS JOIN t10 AS b CROSS JOIN t10 AS c)
SELECT n
FROM t100k;
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 223 ms.
An advantage of the numbers table is that the unique index can be leveraged to optimize certain queries, although not applicable here.
CodePudding user response:
Isn't the first one fetching results from disk, and should therefore be slower?
100,000 integers will fit on around 161 data pages (assuming no compression is in use) - each row will be 11 bytes and consume 2 bytes in the slot array.
When you ran your tests it is possible that the data was in cache already. Even if none was in cache it is very possible that nearly all of the pages were already read into cache by the read ahead mechanism before they were needed so IO waits are minimal and it is again just a CPU bound operation. (You can use SET STATISTICS IO ON to see how many physical reads and read ahead reads were actually required)
Reading rows from a data page in cache is something that SQL Server is, of course, good at. From an execution plan point of view there is no complexity at all. The correct rows can be returned from an index seek operator (ideally or scan operator otherwise) and output straight to the client with no additional operators needed.
The recursive CTE functionality is a generic method that always uses fundamentally the same execution plan. Row(s) from the anchor part are added to an stack spool and then popped (removed) from the spool to feed into a nested loops operator which calculates the recursive part on its inner sub-tree and passes values up the execution plan tree to be added to the stack spool (for further recursion) and returned to the client.
All these execution plan operations take time. I tried for numbers up to 10,000,000 on my local machine. The overall query duration was 2m 6s (of which 38 seconds was spent on PAGELATCH_SH waits in tempdb for the spool)
You can see the "per operator" timings below
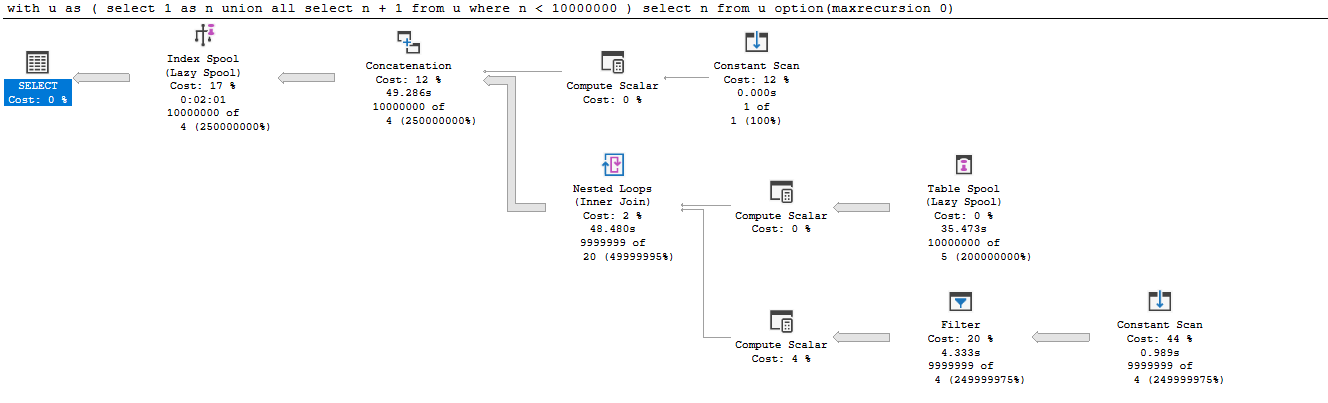
Certainly it would be possible to provide a function like the Postgres generate_series one that is entirely CPU based and just dedicated to the task of supplying incrementing values and this could outperform the disc based table approach but as yet no such dedicated function has been implemented in the product.
CodePudding user response:
When you declare a column as primary key, SQL Server creates a clustered index so it means if you query that table with the primary key SQL Server query optimizer exactly knows where that column is. In other words this query is as efficient as it could be, with minimum CPU time and logical reads.
To see a detailed view of the difference between these two approaches, enable the execution plan WITH Ctrl m run the query and compare two execution plans.