I have two tables and based on the sum of a field in TABLE1 I have to return different datasets from TABLE2:
I am trying to achieve this through a Case statement but getting an error saying subselect must have only one field.
Is there a better way to do this? simply when the sum of a column in table1 is 0 do not select anything from table2
TABLE1:
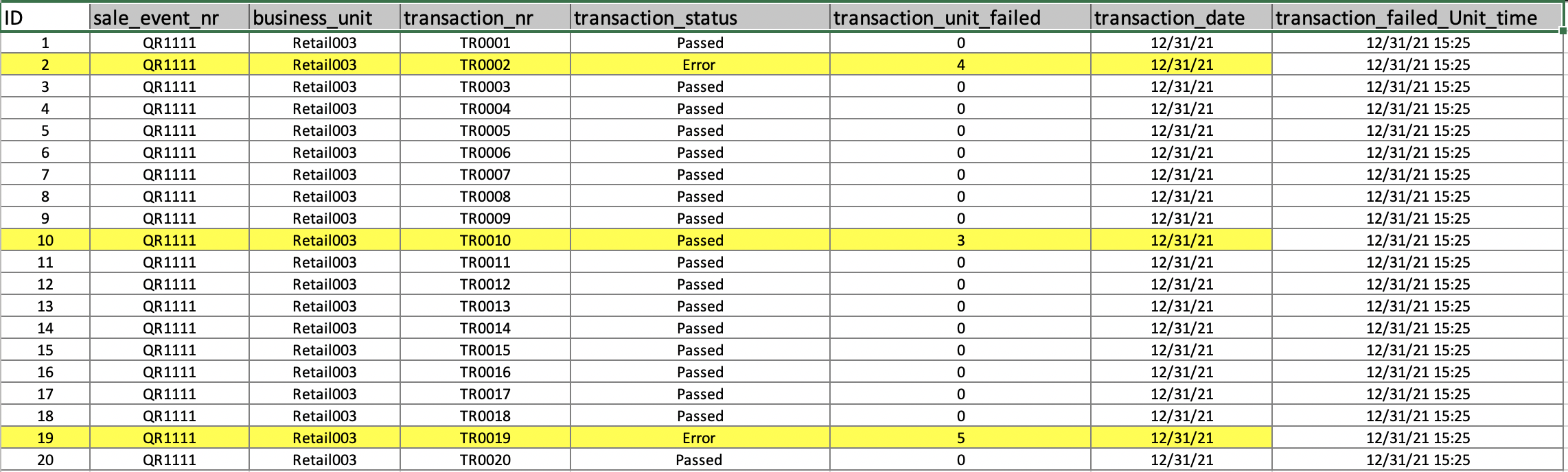
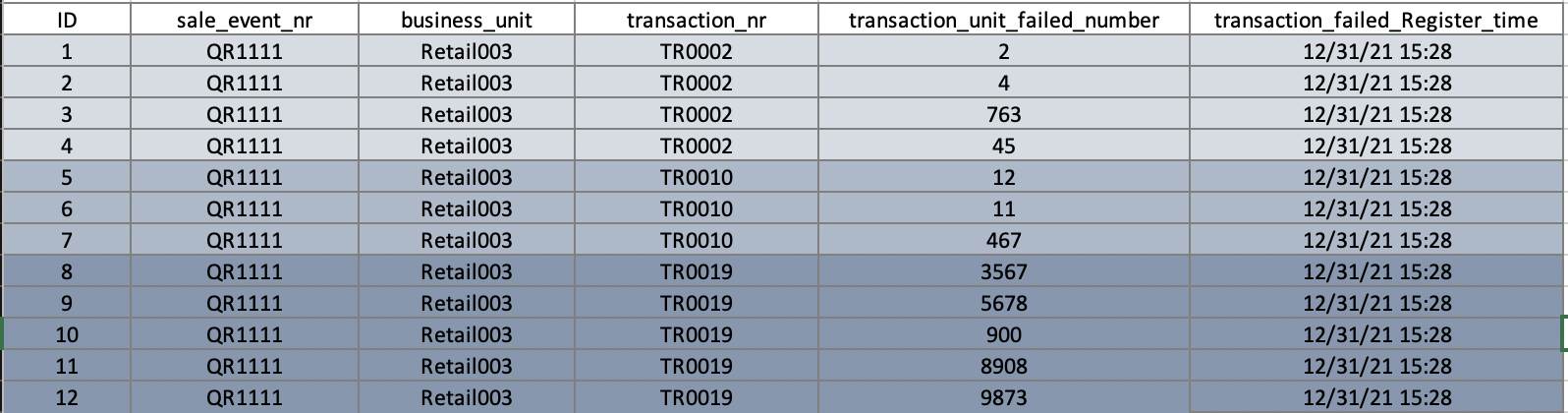
TABLE2:
MY SQL:
SELECT
CASE
WHEN SUM(transaction_unit_failed) > 0
THEN (
SELECT sale_event_nr, business_unit, transaction_nr, transaction_unit_failed_number
FROM TABLE2
)
WHEN SUM(transaction_unit_failed) = 0
THEN (
SELECT sale_event_nr, business_unit, transaction_nr, transaction_unit_failed_number
FROM TABLE2
WHERE 1 = 2
)
FROM TABLE1
CodePudding user response:
select * from table2
where exists (
select 1
from table1
having sum(transaction_unit_failed) > 0
);
Similarly:
select * from table2
where (
select sum(transaction_unit_failed)
from table1
) > 0;
https://dbfiddle.uk/?rdbms=sqlserver_2014&fiddle=3f68d250bc9a3235767b86626092799e
You could certainly write it as a join if there were a compelling reason. It would eliminate the convenience of nicely using * to return only the columns from the one table.
select *
from table2 inner join (
select sum(transaction_unit_failed) as stuf
from table1
) on stuf > 0;
CodePudding user response:
SELECT sale_event_nr, business_unit, transaction_nr, transaction_unit_failed_number
FROM TABLE2
WHERE (SELECT SUM(transaction_unit_failed) > 0
FROM TABLE1)