I was reading on Neo4j, a graph database, and how it compares to the relational model. Here is one thing it mentions in how to query a M2M join for the "Departments" associated with a single user 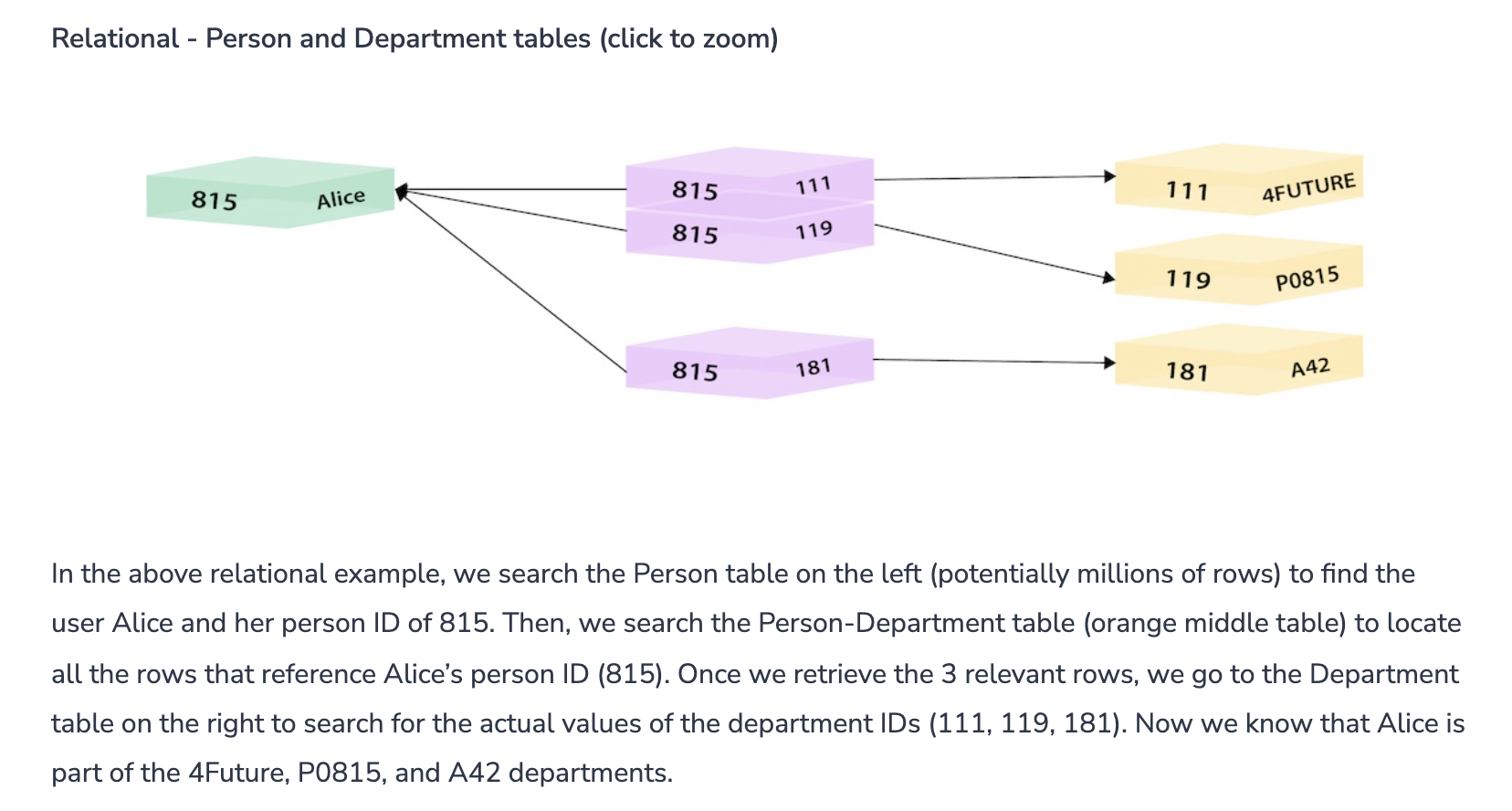
I would think though if I knew beforehand I'm just looking up a single row-by-PK and there are less than 5 departments likely for that user, I would write the query as follows:
SELECT name FROM department WHERE department_id IN (
SELECT department_id FROM PersonDepartment WHERE user_id IN (
SELECT pk FROM Person WHERE name='Alice' # assume unique name
)
)
I'm sure writing this in the more common 'join format' would be optimized by the RDBMS into something closer to the above but I'm using the above just to show how the above query seems like it would take almost no time to execute, or am I wrong here? On the other hand, writing the above in the more concise Cypher format of: [p:Person{name:"Alice"}]-[:BELONGS_TO]->[d:Department] is much simpler to read and write.
CodePudding user response:
Preliminary
To get some issues that confuse the problem out of the way, so that we can answer the question in a straight-forward manner.
The text blurb in the graphic
- It is completely dishonest, the typical Straw Man argument, used to demean what he is against, and to elevate what he is for. He poses the Relational method as something that it is not (a 1960's Record Filing System with
IDsas "Primary Keys"), and then takes it down - Whoopee, he destroyed his own concoction, his Straw Man
- The Relational method remains, unaffected
- Nevertheless, the uneducated will be confused.
- It is completely dishonest, the typical Straw Man argument, used to demean what he is against, and to elevate what he is for. He poses the Relational method as something that it is not (a 1960's Record Filing System with
IDfields as a "Primary Key"
The Relational Model explicitly prohibitsIDs, which are Physical. The PK must be "made up from the data", which is Logical.- Further, the file contains duplicate rows (
IDsdo not provide row uniqueness, which is demanded in the RM) IDscomplicate DML code, and force moreJOINs(that are not required in the equivalent Relational database), which the dear professor is counting on, in his erection of the Straw Man- The
IDsneed to be removed, and proper Relational Keys need to be implemented - Relational Integrity, which is Logical (as distinct from Referential Integrity, which is Physical), is lost, not possible
- Full detail in Relational schema for a book graph.
- Further, the file contains duplicate rows (
No one in the right mind is going to step through those three tables in that way, let alone prescribe it.
- he is using procedural code, such as in a
CURSOR, which is anti-Relational, and stupefyingly slow - the RM and SQL are based on Set Theory, so use set verbs, such as
SELECT, and select only what you need - the proposition is a single set, a single
SELECTfulfils it.
- he is using procedural code, such as in a
Questions
I would think though if I knew beforehand I'm just looking up a single row-by-PK and there are less than 5 departments likely for that user, I would write the query as follows: ...
Definitely not. Even with the IDs
- the population in each table is irrelevant (the PK has an unique index)
- let us assume 10,000 Persons; 10,000 Departments; 16,000,000 PersonDepartments
- performance should never be considered when modelling, or when writing DML code
- it should be considered only when some code performs badly, with a view to improving it.
Other than for the purpose of clarifying your question, that code can be dismissed.
I'm sure writing this in the more common 'join format' would be optimized by the RDBMS
Yes.
with a genuine SQL Platform, it will do many things re optimisation, at many levels: parsing; determination of a Query Plan; considerations of Statistics; etc.
with the freeware "SQLs", it does a mickey mouse version of that (at best), and none at all (at worst). Which is why performance is consideration, everywhere, but that is abnormal; sub-standard.
into something closer to the above
Definitely not. That is a dog's breakfast. It will create a very elegant and optimised Query Plan, and then a hierarchic Query Tree (run-time executable, that can be shared).
but I'm using the above just to show how the above query seems like it would take almost no time to execute, or am I wrong here?
No, you are right. In the sense that either the horrible code example operating on a RFS, or the correct code operating on a Relational database, will execute in millisecs, "almost no time".
Relational Data Model
If you wish to evaluate what he intended in his proposition (what departments does Alice work for), without the dishonesty of his Straw Man, using a Relational database (no IDs, proper Relational Keys), we need a data model.
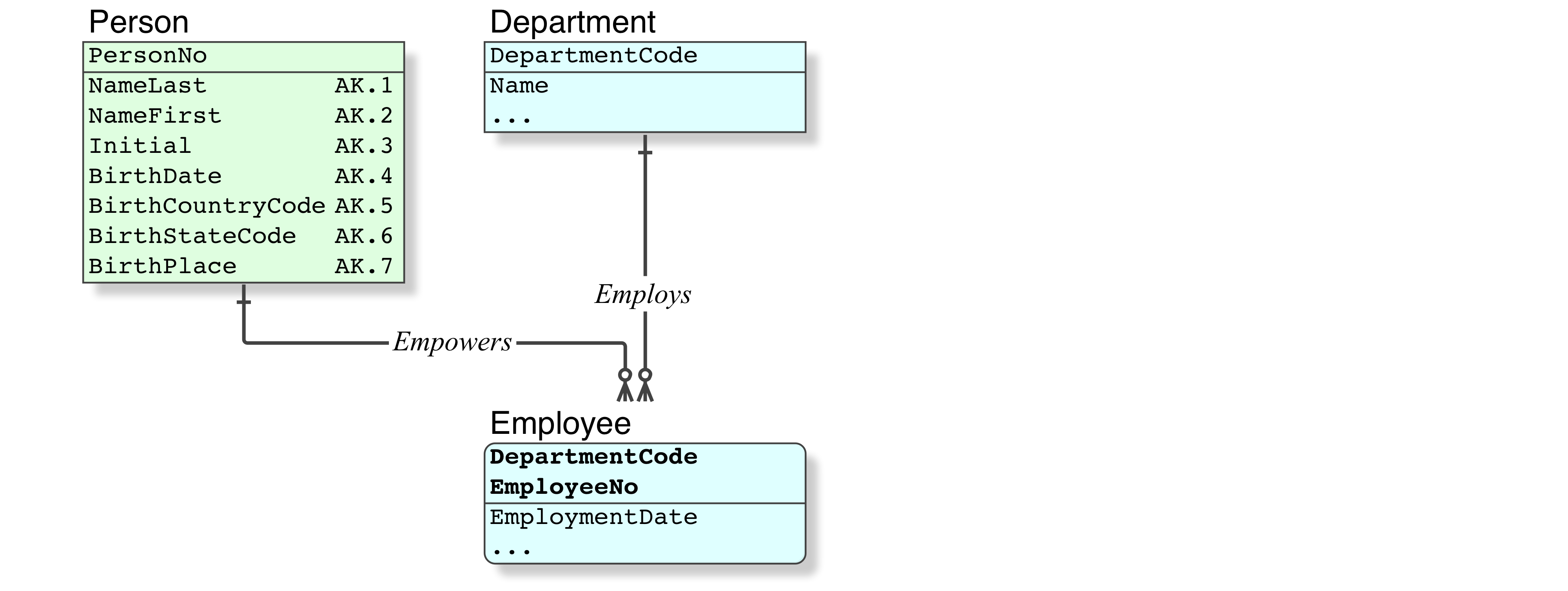
- All my models are rendered in IDEF1X, the one and only Standard for Relational data modelling. (ERD cannot be used.)
- The IDEF1X Introduction is essential reading.
The code is simple.
SELECT NameFirst,
DepartmentCode
FROM Person P
JOIN Employee E ON P.PersonNo = E.EmployeeNo
WHERE NameFirst = "Alice"
This code may produce is more meaningful result set, it is stil a single, simple SELECT.
SELECT NameLast,
NameFirst,
D.Name,
EmploymentDate
FROM Person P
JOIN Employee E ON P.PersonNo = E.EmployeeNo
JOIN Department D ON E.DepartmentCode = D.DepartmentCode
WHERE NameFirst = "Alice"
Comments
One question regarding the "no IDs, proper keys" -- doesn't the PersonNo act the same way as would an autoincrementing PK to identify a person?
Yes.
Except that AUTOINCREMENT/IDENTITY columns have horrendous maintenance problems, thus we do not allow them in Production, thus we do not allow them in Development that is not intended for Production.
The alternative for an INSERT is:
...
PersonNo = (
SELECT MAX( PersonNo ) 1
FROM Person
)
...
- Of course, for high performance OLTP, there are other methods.
- Never use the Oracle method, which is a file of records, each holding a next-sequential-number for some other file.
If we went with PK must be "made up from the data" and no SS# or some uniquely-identifying-person-code, it'd then be just combining a bunch of stuff: FirstName LastName BirthPlace Birthdate (or whatever combination would give enough granularity to guarantee uniqueness)
Yes. That is answered in full detail in the IDEF1X Introduction, please read.
Short answer ...
- this is a true surrogate, not a
RecordID(which is falsely called a surrogate). - the only justification is when
- the natural PK gets too long (here 7 columns and 120 bytes), to be carried into subordinate tables as FKs,
and - the table is the top of a data hierarchy, which therefore does not suffer an Access Path Independence breach, as stipulated in Codd's Relational Model. Which is true in the usage here.
- the natural PK gets too long (here 7 columns and 120 bytes), to be carried into subordinate tables as FKs,
Technically, a surrogate or RecordID) is a breach of the Relational Key Normal Form. A properly placed surrogate does not breach the Access Path Independence Rule (nothing above the breach to be accessed), whereas a RecordID always does. The user does not see the surrogate or RecordID, because it is not data.
Separately, note that ( LastName, FirstName, Initial, Birthdate, BirthCountry, BirthState, BirthPlace ) is an established international convention (not quite a standard) for identifying a person.