I have one table with two columns A and B in hive metadata. I have to generate same random number when value of A and B pair is identical to other records.
Example: value pair 2.0 & 3.0 or 1.0 & 5.0 on those records using HASH function I will get hash_code. This hash_code I will pass to random function to get specific value for each matched records. I can simply pass seed=123 to rand function but I am not able to pass table column to rand function.
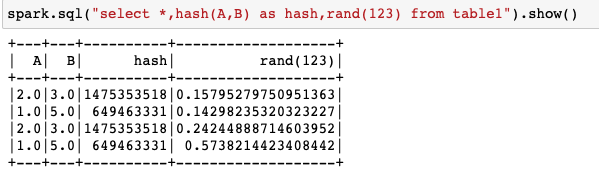
Edit 1:
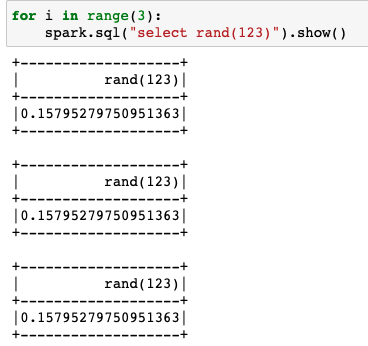
Function rand(123) with same seed will produce identical results.
Passing hash to rand:
spark.sql("select *,rand(hash(A,B)) from table1").show()
Getting below error:
AnalysisException: Input argument to rand must be an integer, long, or null constant.
How to pass hash_code to rand function using spark.sql?
CodePudding user response:
As also pointed out by some comments, rand accepts only one parameter, the seed, which should be a constant, not an column (which is what you obtain from hash(A, B)).
If your purpose is producing a key from the columns A and B, then you shouldn't call any randomizing function. Just use the value of the hash.
CodePudding user response:
Following on my comments, what you're looking for is simply not possible (at least for now) using Spark, for 2 mainly reasons:
- Function
randcan take only constant parameters - Also, it's a non-deterministic function, so calling
rand(hash(A,B))in your dataframe won't give same result for same inputsAandB:
import pyspark.sql.functions as F
# the function rand is called with same value 123, still give different results
spark.range(3).withColumn("rand", F.rand(123)).show()
# --- -------------------
#| id| rand|
# --- -------------------
#| 0|0.24244888714603952|
#| 1| 0.4745014193615499|
#| 2|0.03951602781768582|
# --- -------------------
That said, if your intent is to get a value between [0, 1] from the hash result of A and B, then you could use this trick by dividing the hash by 10...0length_of_hash:
spark.sql("""
SELECT A,
B,
hash(A,B) / rpad('1', length(hash(A,B)) 1, '0') AS Id
FROM table1
""").show()
# --- --- ------------
#| A| B| Id|
# --- --- ------------
#|2.0|3.0|0.1475353518|
#|1.0|5.0| 0.649463331|
#|2.0|3.0|0.1475353518|
#|1.0|5.0| 0.649463331|
# --- --- ------------