I'm creating a summary table that groups my records by country of destination:
SummarybyLocation <- PSTNRecords %>%
group_by(Destination) %>%
summarize(
Calls = n(),
Minutes = sum(durationMinutes),
MaxDuration = max(durationMinutes),
AverageDuration = mean(durationMinutes),
Charges = sum(charge),
Fees = sum(connectionCharge)
)
SummarybyLocation
The resulting table is as follows:
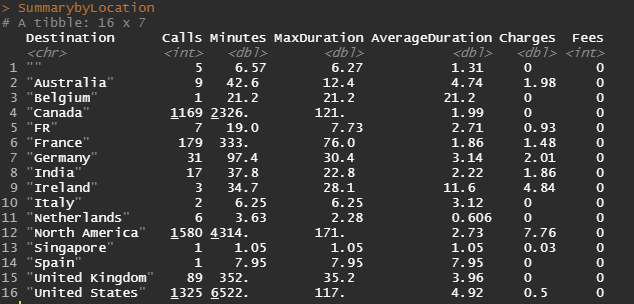
I realized that the Destination values are inconsistent (for example, "France" and "FR" both refer to the same area, and then I have a "North America" that I presume gathers USA and Canada.
I was wondering if there's a way of creating custom groups for these values, so that the aggregation would make more sense. I tried to use the countrycode package to add an iso2c column, but that doesn't resolve the problem of managing other area aggregations like "North America".
I would really appreciate some suggestions on how to handle this.
Thanks in advance!
CodePudding user response:
Here is one possibility for cleaning up the data with a very minimal example. First, I get a list of country names and the 2 and 3 letter abbreviations, and put into a dataframe, countries. Then, I left_join countries to df for the two letter code, which in this case matches FR. Then, I repeat the left_join but with the 3 letter code, which has no matches in this case. Then, I coalesce the two new columns together, i.e., Country.x and Country.y. Then, I use case_when to multiple if-else statements. First, if Country is not an NA, then I replace Destination with the full country name. This is where you can add in other arguments if you have other items (e.g., Europe) that you might also need to fix. Next, I replace North America with "United States-Canada-Mexico". Finally, I remove the columns that start with "Country".
library(XML)
library(RCurl)
library(rlist)
library(tidyverse)
theurl <-
getURL("https://www.iban.com/country-codes",
.opts = list(ssl.verifypeer = FALSE))
countries <- readHTMLTable(theurl)
countries <-
list.clean(countries, fun = is.null, recursive = FALSE)[[1]]
df %>%
left_join(.,
countries %>% select(Country, `Alpha-2 code`),
by = c("Destination" = "Alpha-2 code")) %>%
left_join(.,
countries %>% select(Country, `Alpha-3 code`),
by = c("Destination" = "Alpha-3 code")) %>%
mutate(
Country = coalesce(Country.x, Country.y),
Destination = case_when(!is.na(Country) ~ Country,
Destination == "North America" ~ "United States-Canada-Mexico",
TRUE ~ Destination
)) %>%
select(-c(starts_with("Country")))
Output
Destination durationMinutes charge connectionCharge
1 France 6.57 0.00 0
2 France 3.34 1.94 0
3 United States 234.40 3.00 0
4 United States-Canada-Mexico 23.40 2.00 0
However, if you have a lot of different variations, then you probably just want to create a simple dataframe with the substitutions, as then you can just do one left_join.
Another option is to also add in a Continent column, which you could get from countrycode.
library(countrycode)
countrycode(sourcevar = df$Destination,
origin = "country.name",
destination = "continent")
[1] NA "Europe" "Americas" NA
Data
df <- structure(list(Destination = c("FR", "France", "United States",
"North America"), durationMinutes = c(6.57, 3.34, 234.4, 23.4
), charge = c(0, 1.94, 3, 2), connectionCharge = c(0, 0, 0, 0
)), class = "data.frame", row.names = c(NA, -4L))
CodePudding user response:
The {countrycode} package can deal with custom names/codes easily...
library(tidyverse)
library(countrycode)
PSTNRecords <- tibble::tribble(
~Destination, ~durationMinutes, ~charge, ~connectionCharge,
"FR", 1, 2.5, 0.3,
"France", 1, 2.5, 0.3,
"United States", 1, 2.5, 0.3,
"USA", 1, 2.5, 0.3,
"North America", 1, 2.5, 0.3
)
# see what special codes/country names you have to deal with
iso3cs <- countrycode(PSTNRecords$Destination, "country.name", "iso3c", warn = FALSE)
unique(PSTNRecords$Destination[is.na(iso3cs)])
#> [1] "FR" "North America"
# decde how to deal with them
custom_matches <- c("FR" = "FRA", "North America" = "USA")
# use your custom codes
PSTNRecords %>%
mutate(iso3c = countrycode(Destination, "country.name", "iso3c", custom_match = custom_matches))
#> # A tibble: 5 × 5
#> Destination durationMinutes charge connectionCharge iso3c
#> <chr> <dbl> <dbl> <dbl> <chr>
#> 1 FR 1 2.5 0.3 FRA
#> 2 France 1 2.5 0.3 FRA
#> 3 United States 1 2.5 0.3 USA
#> 4 USA 1 2.5 0.3 USA
#> 5 North America 1 2.5 0.3 USA