I'm looking at removing specific terms before certain words in a dataframe column.
data = {'Code':['001', '002', '003', '004', '005', '006','007'],
'Territory':['Kinshasa West', 'West Kivu', 'East Tamaki', 'Sydney North','Sydney South','Brisbane East Suburb','Wattle Downs East']}
df = pd.DataFrame(data)
df
Code Territory
0 001 Kinshasa West
1 002 West Kivu
2 003 East Tamaki
3 004 Sydney North
4 005 Sydney South
5 006 Brisbane East Suburb
6 007 Wattle Downs East
I'm interested in removing words "West", "East", "North", "South" only if they are the last words in the column value. However, they should not be removed if they come before the last word.
Expected output:
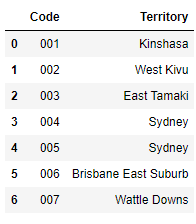
Code Territory
0 001 Kinshasa
1 002 West Kivu
2 003 East Tamaki
3 004 Sydney
4 005 Sydney
5 006 Brisbane East Suburb
6 007 Wattle Downs
I'm able to filter out the specific terms from the column values but making use of word positions is the issue at the moment.
CodePudding user response:
You can use regex and .apply().
import re
def remove_nsew(territory):
return re.sub(" (North|South|East|West)$", "", territory)
df["Territory"] = df["Territory"].apply(remove_nsew)
CodePudding user response:
Does the data start out as a list? You can use string manipulation on the list or convert it to a list and modify the dictionary
data = {'Code':['001', '002', '003', '004', '005', '006','007'],
'Territory':['Kinshasa West', 'West Kivu', 'East Tamaki', 'Sydney North','Sydney South','Brisbane East Suburb','Wattle Downs East']}
list1 = list(data.values())
for index,value in enumerate(list1[1]):
if(value.endswith("West")):
list1[1][index] = value.replace("West", "")