I have a dataframe with 2 columns: Date and LMP and there are totals of 8760 rows. This is the dummy dataframe:
import pandas as pd
import numpy as np
df = pd.DataFrame({'Date': pd.date_range('2023-01-01 00:00', '2023-12-31 23:00', freq='1H'), 'LMP': np.random.randint(10, 20, 8760)})
I extract month from the date and then created the season column for the specific dates. Like this
df['month'] = pd.DatetimeIndex(df['Date']).month
season = []
for i in df['month']:
if i <= 2 or i == 12:
season.append('Winter')
elif 2 < i <= 5:
season.append('Spring')
elif 5 < i <= 8:
season.append('Summer')
else:
season.append('Autumn')
df['Season'] = season
df2 = df.groupby(['month']).mean()
df3 = df.groupby(['Season']).mean()
print(df2['LMP'])
print(df3['LMP'])
Output:
**month**
1 20.655113
2 20.885532
3 19.416946
4 22.025248
5 26.040606
6 19.323863
7 51.117965
8 51.434093
9 21.404680
10 14.701989
11 20.009590
12 38.706160
**Season**
Autumn 18.661426
Spring 22.499365
Summer 40.856845
Winter 26.944382
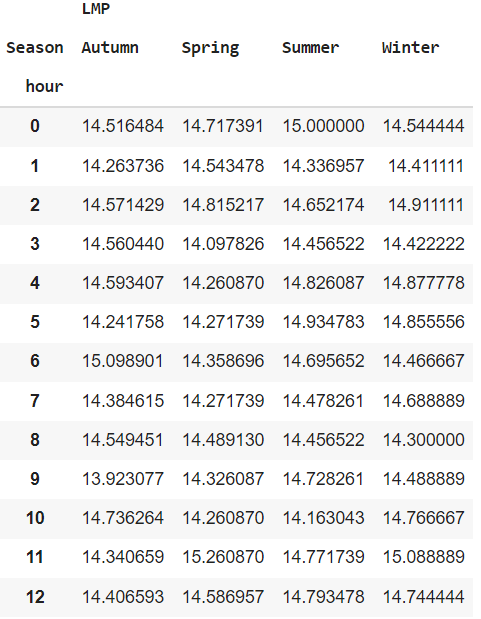
But I want the output to be in 24 hour average for both monthly and seasonal.
Desired Output:
for seasonal 24 hours average
For monthyl 24 hours average

Note: in the monthyl 24 hour average columns are months(1,2,3,4,5,6,7,8,9,10,11,12) and rows are hours(starting from 0). Can anyone help?
CodePudding user response:
try:
df['hour']=pd.DatetimeIndex(df['Date']).hour
dft = df[['Season', 'hour', 'LMP']]
dftg = dft.groupby(['hour', 'Season'])['LMP'].mean()
dftg.reset_index().pivot(index='hour', columns='Season')
result: