I am working on a requirement where I need to assign particular value to NaN based on the variable upper, which is my upper range of standard deviation Here is a sample code-
data = {'year': ['2014','2014','2015','2014','2015','2015','2015','2014','2015'],
'month':['Hyundai','Toyota','Hyundai','Toyota','Hyundai','Toyota','Hyundai','Toyota',"Toyota"],
'make': [23,34,32,22,12,33,44,11,21]
}
df = pd.DataFrame.from_dict(data)
df=pd.pivot_table(df,index='month',columns='year',values='make',aggfunc=np.sum)
upper=df.mean() 3*df.std()
This is just the sample data, the real data is huge, based on upper's value for every year, I need to filter the year column accordingly.
Sample I/P's:-
df-
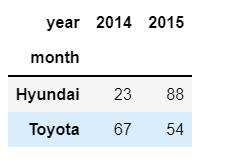
upper std dev-

Desired O/P-
Based on the upper std deviation values in individual year, it should convert value as NaN if the value<upper. Eg 2014 has upper=138, so only in 2014's column, if value<upper, convert it to NaN. 2014's upper value is only applicable in 2014 itself, and the same goes for 2015.
CodePudding user response:
IIUC use DataFrame.lt for compare Dataframe by Series and then set NaNs if match by DataFrame.mask:
print (df.lt(upper))
year 2014 2015
month
Hyundai True True
Toyota True True
df = df.mask(df.lt(upper))
print (df)
year 2014 2015
month
Hyundai NaN NaN
Toyota NaN NaN