I have an array with the shape (29,2):
arr = [[ 405.95168576 1033. ]
[ 406.23572583 1033. ]
[ 407.49812423 1028. ]
[ 402.66145728 1029. ]
[ 404.11080846 1032. ]
[ 401.75897118 1033. ]
[ 402.29352509 1029. ]
[ 402.34504752 1024. ]
[ 402.69938672 1027. ]
[ 400.55298544 1029. ]
[ 401.41432112 1027. ]
[ 400.89318038 1027. ]
[ 401.07444532 1029. ]
[ 400.43212193 1033. ]
[ 400.38178995 1027. ]
[ 399.89895625 1025. ]
[ 399.88394127 1031. ]
[ 399.97766298 1021. ]
[ 399.68084993 1027. ]
[ 399.65810987 1029. ]
[ 399.40565484 1020. ]
[ 399.34339145 1023. ]
[ 399.39613518 1019. ]
[ 399.37733697 1020. ]
[ 399.38314402 1020. ]
[ 399.47479381 1025. ]
[ 399.44134998 1025. ]
[ 399.43511907 1020. ]
[ 399.40346787 1020. ]]
I would like to filter this array to find whether each row contains the maximum value for column arr[:,0], of all rows in which the value of arr[:,1] is equal to or lower than the one contained in that row.
At the moment, I have the following code, which produces the correct result:
import numpy as np
res = np.array([])
for i in range(arr.shape[0]):
print(np.max(arr[:,0][arr[:,1] <= arr[i][1]]))
if arr[i][0] >= np.max(arr[:,0][arr[:,1] <= arr[i][1]]):
res = np.hstack((res, True))
else:
res = np.hstack((res, False))
print(res)
Is there a way to perform this operation in pure numpy, i.e. without using the loop?
CodePudding user response:
The following approach:
- uses
np.lexsortto order the array first by the second column ascending, then by the first column descending - uses
np.maximum.accumulateto calculate the accumulated maxima - reverses the sorted order back to the original order to be able to compare
import numpy as np
arr = np.array([[405.95168576, 1033], [406.23572583, 1033], [407.49812423, 1028], [402.66145728, 1029], [404.11080846, 1032], [401.75897118, 1033], [402.29352509, 1029], [402.34504752, 1024], [402.69938672, 1027], [400.55298544, 1029], [401.41432112, 1027], [400.89318038, 1027], [401.07444532, 1029], [400.43212193, 1033], [400.38178995, 1027], [399.89895625, 1025], [399.88394127, 1031], [399.97766298, 1021], [399.68084993, 1027], [399.65810987, 1029], [399.40565484, 1020], [399.34339145, 1023], [399.39613518, 1019], [399.37733697, 1020], [399.38314402, 1020], [399.47479381, 1025], [399.44134998, 1025], [399.43511907, 1020], [399.40346787, 1020]])
# sort on arr[:,1] ascending then on arr[:,0] descending, return the indices
ind_sorted = np.lexsort((-arr[:, 0], arr[:, 1]))
# calculate the accumulated maxima of the sorted list
max_per_level_sorted = np.maximum.accumulate(arr[ind_sorted, 0])
# get the ordering that maps the sorted values back to the originals
reverse_sorted = np.argsort(ind_sorted)
# get the maxima in the order of the original array
max_per_level = max_per_level_sorted[reverse_sorted]
res = arr[:, 0] >= max_per_level
print(res.astype(int)) # res is a boolean array, show it as integers
[0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0]
If you really want to, you can compress all this together:
ind_sorted = np.lexsort((-arr[:, 0], arr[:, 1]))
res = arr[:, 0] >= np.maximum.accumulate(arr[ind_sorted, 0])[np.argsort(ind_sorted)]
print(res.astype(int))
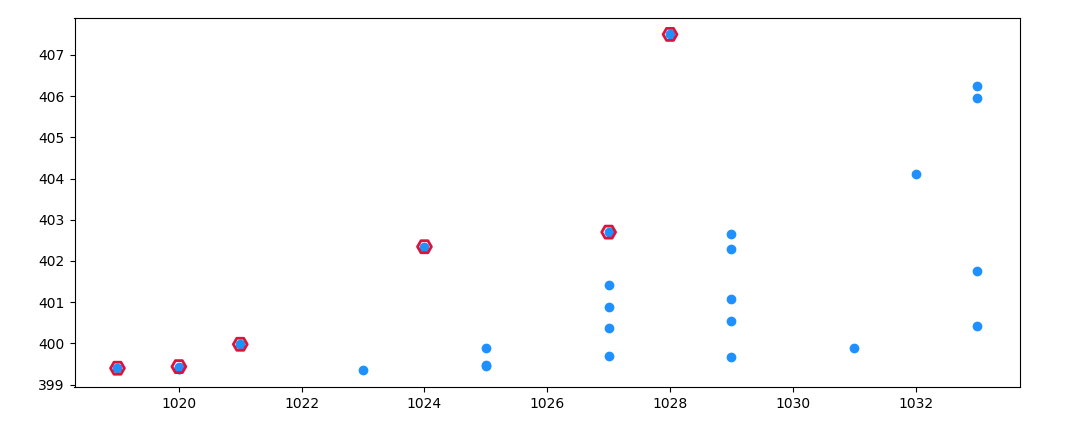
Here is a visualization:
import matplotlib.pyplot as plt
plt.scatter(arr[:, 1], arr[:, 0], color='dodgerblue')
plt.scatter(arr[res, 1], arr[res, 0], fc='none', ec='crimson', lw=2, s=100, marker='H')