I have a csv file that looks something like this:
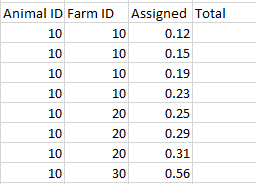
I'm trying to extract the max and min values from the "Assigned" column based on the combined values of the "Animal ID" and "Farm ID" columns.
Ex. if the "Animal ID" = 10 and "Farm ID" = 10, I need to find its max value (0.23 in this case) and its min value (0.12 in this case) and subtract the two. Then, I want to do the same for when "Animal ID" = 10 and "Farm ID" = 20 and so on. I tried the following, however, I get the following error: KeyError: 'Assigned'. I'm not sure where I'm going wrong. Also, if there's a better way to achieve this than the method I'm using, I'd really appreciate learning about that.
This is what I have done so far:
if df['AnimalID'].all() ==0 and df['Farm ID'].all() ==0:
print(df.loc['Assigned'].max() - df.loc['Assigned'].min())
Expected Output for Animal ID = 10 and Farm ID = 10: 0.11
Expected Output for Animal ID = 10 and Farm ID = 20: 0.06
CodePudding user response:
Use groupy_apply:
out = df.groupby(['Animal ID', 'Farm ID'], as_index=False)['Assigned'] \
.apply(lambda x: x.max() - x.min())
print(out)
# Output
Animal ID Farm ID Assigned
0 10 10 0.11
1 10 20 0.06
2 10 30 0.00