I have a dataframe which is very big. I don't want to iterate over each row. I want to classify them based on the maximum of each row. If the values is greater than 0.45 is in class 3, if<0.2 in class 1, if >0.45 in class 3. Here is a sample of the dataframe:
import pandas as pd
import numpy as np
from pandas.tseries.holiday import USFederalHolidayCalendar as calendar
df = pd.DataFrame()
df['c0'] = [ 0.4656, 0.1530,0.1854 ]
df['c1'] = [ 0.4452, 0.2064, 0.1416]
df['c2'] = [0.4224 , 0.4224, 0.1800]
df['max'] = df.max(axis=1)
df
And the dataframe which I want is:
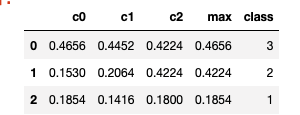
Could you please help me with that?
CodePudding user response:
IIUC, you could use np.select to assign class values to rows:
df['class'] = np.select([df['max']>0.45, df['max']<0.2], [3, 1], 2)
Output:
c0 c1 c2 max class
0 0.4656 0.4452 0.4224 0.4656 3
1 0.1530 0.2064 0.4224 0.4224 2
2 0.1854 0.1416 0.1800 0.1854 1