I am using pyspark==2.3.1. I have performed data preprocessing on the data using pandas now I want to convert my preprocessing function into pyspark from pandas. But while reading the data CSV file using pyspark lot of values become null of the column that has actually some values. If I try to perform any operation on this dataframe then it is swapping the values of the columns with other columns. I also tried different versions of pyspark. Please let me know what I am doing wrong. Thanks
Result from pyspark:
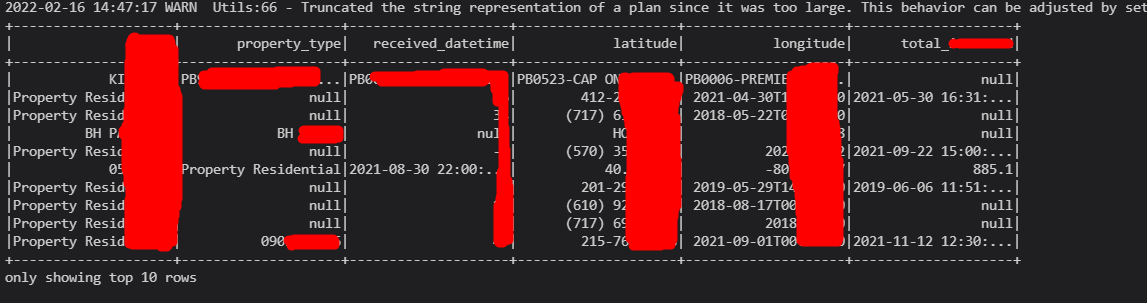
The values of the column "property_type" have null but the actual dataframe has some value instead of null.
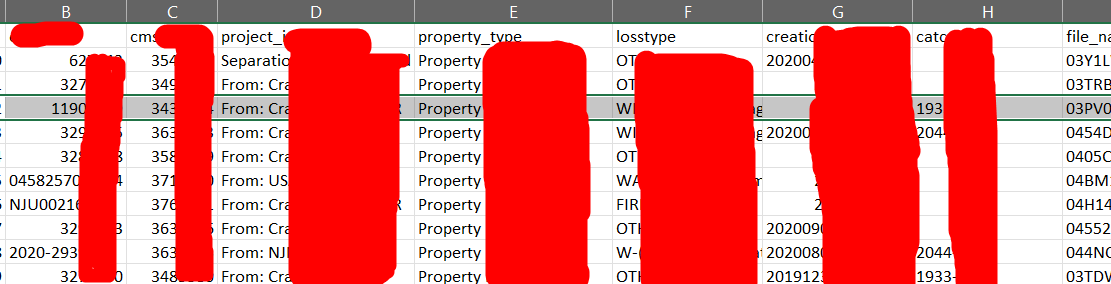
CSV File:
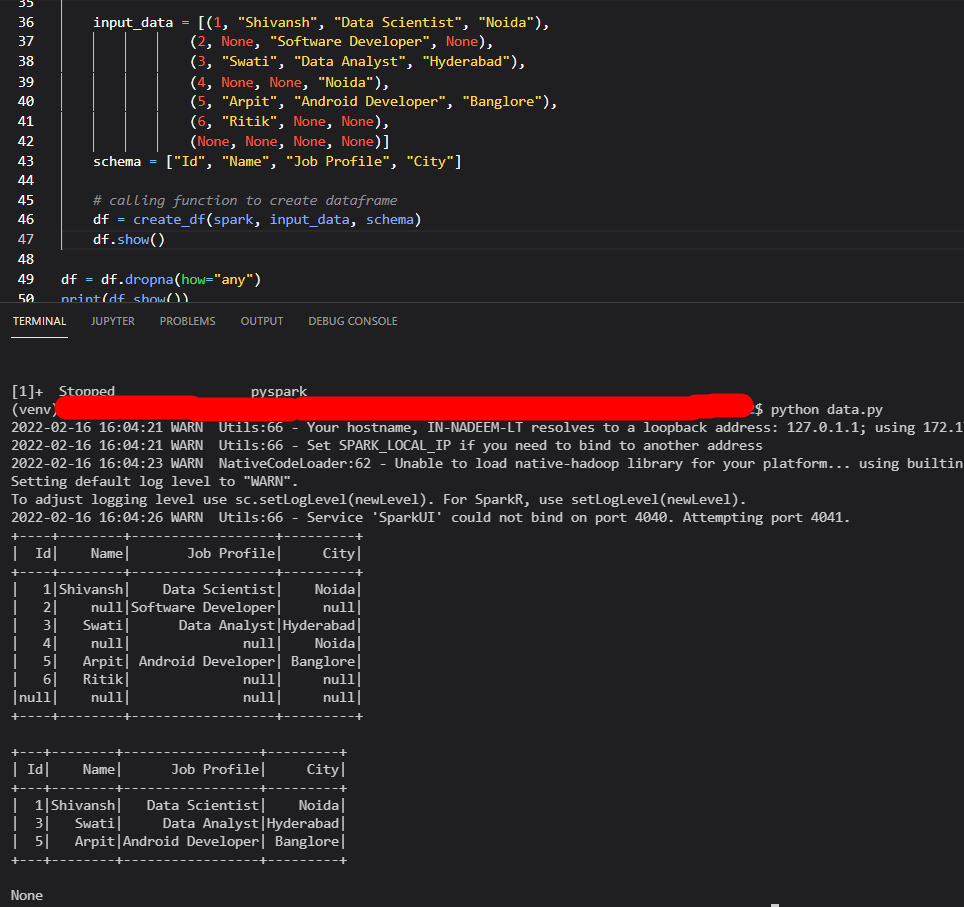
But pyspark is working fine with small datasets. i.e.
CodePudding user response:
In our we faced the similar issue. Things you need to check
- Check wether your data as " [double quotes] pypark would consider this as delimiter and data looks like malformed
- Check wether your csv data as multiline We handled this situation by mentioning the following configuration
spark.read.options(header=True, inferSchema=True, escape='"').option("multiline",'true').csv(schema_file_location)
CodePudding user response:
Are you limited to use CSV fileformat?
Try parquet. Just save your DataFrame in pandas with .to_parquet() instead of .to_csv(). Spark works with this format really well.