I have a CSV file, of the following type:
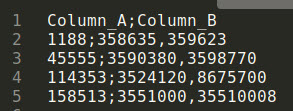
I need to reformat it to the following form:
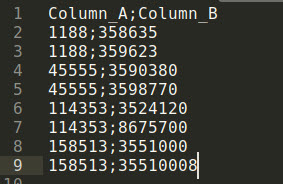
Could you tell me please, how can column Column_B be divided into rows, but only so that column Column_A is filled with corresponding values according to column Column_B.
Thank you very much.
CodePudding user response:
I would recommend leveraging df.explode() after modifying Column_B to a list-type:
df = pd.read_csv(text, sep=';')
df['Column_B'] = df['Column_B'].str.split(',')
df = df.explode('Column_B')
df.to_csv('test.csv', sep=';', index=False)
CodePudding user response:
At first, you need to retrieve your CSV file content into raw text.
content = "..."
final_content = ""
# a readable solution
for line in content.split('\n'):
key = line.split(';')[0]
vals = line.split(';')[1].split(',')
final_content = key ";" vals[0] "\n"
final_content = key ";" vals[1] "\n"
The same solution, but looks shorter
final_content = "\n".join([line.split(';')[0] ":"line.split(';')[1].split(",")[0] '\n' line.split(';')[0] ":"line.split(';')[1].split(",")[1] for line in content.split('\n')])
CodePudding user response:
Basically you need to split lines and create those two lines out of a single line. Here is a step by step solution: (I explained it with my variable names)
with open('old.csv') as f:
# storing the header
header = next(f)
res = []
for line in f:
with_semicolon_part, without_semicolumn_part = line.rstrip().split(',')
first_part, second_part = with_semicolon_part.split(';')
lst = [first_part, second_part, without_semicolumn_part]
res.append(lst)
# creating new csv file with our `res`.
with open('new.csv', mode='w') as f:
f.write(header)
for lst in res:
f.write(lst[0] ';' lst[1] '\n')
f.write(lst[0] ';' lst[2] '\n')
CodePudding user response:
import pandas as pd
import numpy as np
df = pd.read_csv(<"fname.csv">, sep=";")
df = pd.DataFrame(np.repeat(df.values, 2, axis=0), columns=df.columns)
df.iloc[1::2,1] = df.iloc[1::2,1].str.replace(".*,", "", regex=True)
df.iloc[::2,1] = df.iloc[::2,1].str.replace(",.*", "", regex=True)