I'm a beginner in Python. I have a df named df_opensports with lot of columns. One column is named 'Sub_Categoria'. Another Column is named 'Name'. I need to fill empty values from 'Sub_Categoria' with the first word from the same 'Name' column index. For example, if in idx 10 from df_opensports , the value from 'Sub_Categoria' is empty, then, fill it with the first word from the 'Name' string in the same index. I´ve seen many posts, and tried different ways, like this:
df_opensports.loc[df_opensports.Sub_Categoria == '', 'Sub_Categoria']=df_opensports.Name.str.split().str.get(0)
but the result for each empty value in 'Sub_Categoria' is still empty....What am I doing Wrong?
An example of de df :
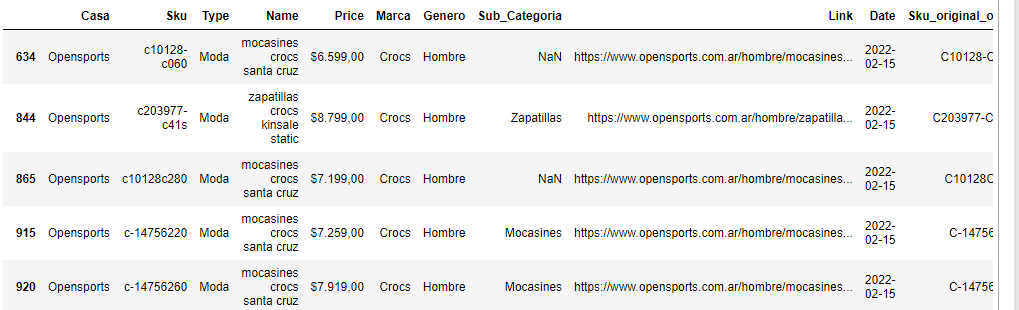
for example, in the first line , instead of NaN, I need to get 'mocasines'
Thanks in advance
CodePudding user response:
Not the best idea, but I believe it would solve your problem:
for index, row in df_opensports.iterrows():
if row["Sub_Categoria"] == None:
df_opensports.loc[index, "Sub_Categoria"] = row["Name"].split(" ")[0]
Thanks to your comment, I remembered another approach for this question:
df_opensports.Sub_Categoria.fillna(df_opensports.Name.apply(lambda x: x.split(" ")[0]), inplace=True)