I'm trying to execute SQL SELECT command using Databricks with AWS Redshift.
I went through 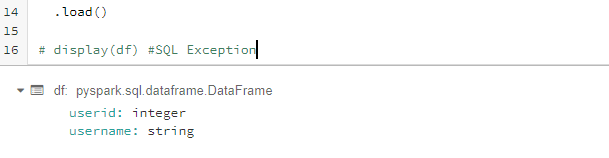
But when I would uncomment the last line and try to see SQL SELECT results:
java.sql.SQLException: Exception thrown in awaitResult:
at com.databricks.spark.redshift.JDBCWrapper.executeInterruptibly(RedshiftJDBCWrapper.scala:223)
at com.databricks.spark.redshift.JDBCWrapper.executeInterruptibly(RedshiftJDBCWrapper.scala:197)
at com.databricks.spark.redshift.RedshiftRelation.$anonfun$getRDDFromS3$1(RedshiftRelation.scala:212)
at scala.runtime.java8.JFunction0$mcZ$sp.apply(JFunction0$mcZ$sp.java:23)
at com.databricks.backend.daemon.driver.ProgressReporter$.withStatusCode(ProgressReporter.scala:377)
at com.databricks.backend.daemon.driver.ProgressReporter$.withStatusCode(ProgressReporter.scala:363)
at com.databricks.spark.util.SparkDatabricksProgressReporter$.withStatusCode(ProgressReporter.scala:34)
at com.databricks.spark.redshift.RedshiftRelation.getRDDFromS3(RedshiftRelation.scala:212)
at com.databricks.spark.redshift.RedshiftRelation.buildScan(RedshiftRelation.scala:157)
at org.apache.spark.sql.execution.datasources.DataSourceStrategy$.$anonfun$apply$3(DataSourceStrategy.scala:426)
at org.apache.spark.sql.execution.datasources.DataSourceStrategy$.$anonfun$pruneFilterProject$1(DataSourceStrategy.scala:460)
at org.apache.spark.sql.execution.datasources.DataSourceStrategy$.pruneFilterProjectRaw(DataSourceStrategy.scala:538)
at org.apache.spark.sql.execution.datasources.DataSourceStrategy$.pruneFilterProject(DataSourceStrategy.scala:459)
at org.apache.spark.sql.execution.datasources.DataSourceStrategy$.apply(DataSourceStrategy.scala:426)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$2(QueryPlanner.scala:69)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$1(QueryPlanner.scala:69)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:489)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:100)
at org.apache.spark.sql.execution.SparkStrategies.plan(SparkStrategies.scala:75)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$4(QueryPlanner.scala:85)
at scala.collection.TraversableOnce.$anonfun$foldLeft$1(TraversableOnce.scala:162)
at scala.collection.TraversableOnce.$anonfun$foldLeft$1$adapted(TraversableOnce.scala:162)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:162)
at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:160)
at scala.collection.AbstractIterator.foldLeft(Iterator.scala:1429)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$3(QueryPlanner.scala:82)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490)
at org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:100)
at org.apache.spark.sql.execution.SparkStrategies.plan(SparkStrategies.scala:75)
at org.apache.spark.sql.execution.QueryExecution$.createSparkPlan(QueryExecution.scala:493)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$sparkPlan$1(QueryExecution.scala:129)
at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:134)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:180)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:180)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:129)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:122)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executedPlan$1(QueryExecution.scala:141)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:141)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:136)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$simpleString$2(QueryExecution.scala:199)
at org.apache.spark.sql.execution.ExplainUtils$.processPlan(ExplainUtils.scala:115)
at org.apache.spark.sql.execution.QueryExecution.simpleString(QueryExecution.scala:199)
at org.apache.spark.sql.execution.QueryExecution.org$apache$spark$sql$execution$QueryExecution$$explainString(QueryExecution.scala:260)
at org.apache.spark.sql.execution.QueryExecution.explainStringLocal(QueryExecution.scala:226)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$5(SQLExecution.scala:123)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:273)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$1(SQLExecution.scala:104)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854)
at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:77)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:223)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3823)
at org.apache.spark.sql.Dataset.collectResult(Dataset.scala:3031)
at com.databricks.backend.daemon.driver.OutputAggregator$.withOutputAggregation0(OutputAggregator.scala:268)
at com.databricks.backend.daemon.driver.OutputAggregator$.withOutputAggregation(OutputAggregator.scala:102)
at com.databricks.backend.daemon.driver.PythonDriverLocalBase.generateTableResult(PythonDriverLocalBase.scala:526)
at com.databricks.backend.daemon.driver.PythonDriverLocal.computeListResultsItem(PythonDriverLocal.scala:672)
at com.databricks.backend.daemon.driver.PythonDriverLocalBase.genListResults(PythonDriverLocalBase.scala:490)
at com.databricks.backend.daemon.driver.PythonDriverLocal.$anonfun$getResultBufferInternal$1(PythonDriverLocal.scala:727)
at com.databricks.backend.daemon.driver.PythonDriverLocal.withInterpLock(PythonDriverLocal.scala:608)
at com.databricks.backend.daemon.driver.PythonDriverLocal.getResultBufferInternal(PythonDriverLocal.scala:687)
at com.databricks.backend.daemon.driver.DriverLocal.getResultBuffer(DriverLocal.scala:634)
at com.databricks.backend.daemon.driver.PythonDriverLocal.outputSuccess(PythonDriverLocal.scala:650)
at com.databricks.backend.daemon.driver.PythonDriverLocal.$anonfun$repl$6(PythonDriverLocal.scala:221)
at com.databricks.backend.daemon.driver.PythonDriverLocal.withInterpLock(PythonDriverLocal.scala:608)
at com.databricks.backend.daemon.driver.PythonDriverLocal.repl(PythonDriverLocal.scala:208)
at com.databricks.backend.daemon.driver.DriverLocal.$anonfun$execute$11(DriverLocal.scala:526)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:266)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:261)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:258)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionContext(DriverLocal.scala:50)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:305)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:297)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionTags(DriverLocal.scala:50)
at com.databricks.backend.daemon.driver.DriverLocal.execute(DriverLocal.scala:503)
at com.databricks.backend.daemon.driver.DriverWrapper.$anonfun$tryExecutingCommand$1(DriverWrapper.scala:689)
at scala.util.Try$.apply(Try.scala:213)
at com.databricks.backend.daemon.driver.DriverWrapper.tryExecutingCommand(DriverWrapper.scala:681)
at com.databricks.backend.daemon.driver.DriverWrapper.getCommandOutputAndError(DriverWrapper.scala:522)
at com.databricks.backend.daemon.driver.DriverWrapper.executeCommand(DriverWrapper.scala:634)
at com.databricks.backend.daemon.driver.DriverWrapper.runInnerLoop(DriverWrapper.scala:427)
at com.databricks.backend.daemon.driver.DriverWrapper.runInner(DriverWrapper.scala:370)
at com.databricks.backend.daemon.driver.DriverWrapper.run(DriverWrapper.scala:221)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.postgresql.util.PSQLException: ERROR: UNLOAD destination is not supported. (Hint: only S3 based unload is allowed)
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2477)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2190)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:300)
at org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:428)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:354)
at org.postgresql.jdbc.PgPreparedStatement.executeWithFlags(PgPreparedStatement.java:169)
at org.postgresql.jdbc.PgPreparedStatement.execute(PgPreparedStatement.java:158)
at com.databricks.spark.redshift.JDBCWrapper.$anonfun$executeInterruptibly$1(RedshiftJDBCWrapper.scala:197)
at com.databricks.spark.redshift.JDBCWrapper.$anonfun$executeInterruptibly$1$adapted(RedshiftJDBCWrapper.scala:197)
at com.databricks.spark.redshift.JDBCWrapper.$anonfun$executeInterruptibly$2(RedshiftJDBCWrapper.scala:215)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
More details:
Databricks Runtime Version:
9.1 LTS (includes Apache Spark 3.1.2, Scala 2.12)
I've tried the same with JDBC redshift Driver (using URL prefix jdbc:redshift)
Then I had to install com.github.databricks:spark-redshift_2.11:master-SNAPSHOT to my Databricks Cluster Libraries.
The result was the same.
Data inside Redshift (sample data created by AWS):
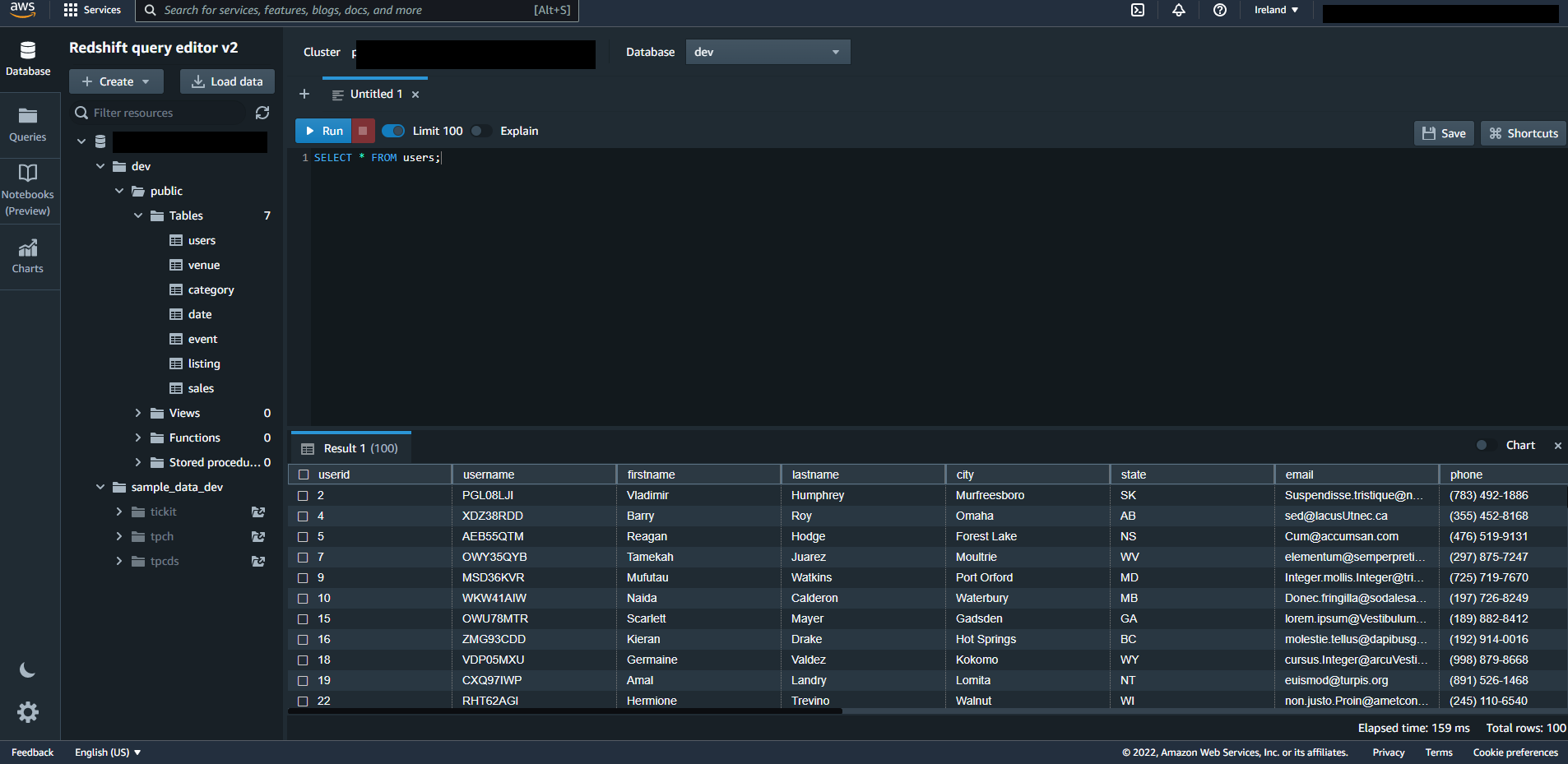
Does anyone have an idea what is wrong with my configuration?
CodePudding user response:
one of the errors could be in option('url'). it should be jdbc:redshift not jdbc:postgresql, use redshift and re-try
CodePudding user response:
After several tries, I figure out the solution.
- I deleted temporary keys
- I used
forward_spark_s3_credentials - I attached IAM Role to the EC2's (cluster)
- I used
s3apath instead mounteddbfsdirectory - Update the cluster's libraries:
- I used
RedshiftJDBC42_no_awssdk_1_2_55_1083.jar - and deleted
com.github.databricks:spark-redshift_2.11:master-SNAPSHOT.
- I used
Final configuration:
df = spark.read \
.format("com.databricks.spark.redshift") \
.option("url", "jdbc:redshift://<REDSHIFT_URL>:<DB_PORT>/<DB_NAME>") \
.option("forward_spark_s3_credentials", "true") \
.option("user", "XXX") \
.option("password", "XXX") \
.option("tempdir", "s3a://<MY_S3_BUCKET>/...") \
.option("query", "SELECT userid, username FROM users") \
.load()
display(df)
Libraries set up in the cluster:
(Probably only Redshift JDBC driver is needed. I also added libs from AWS bundle (which can be found 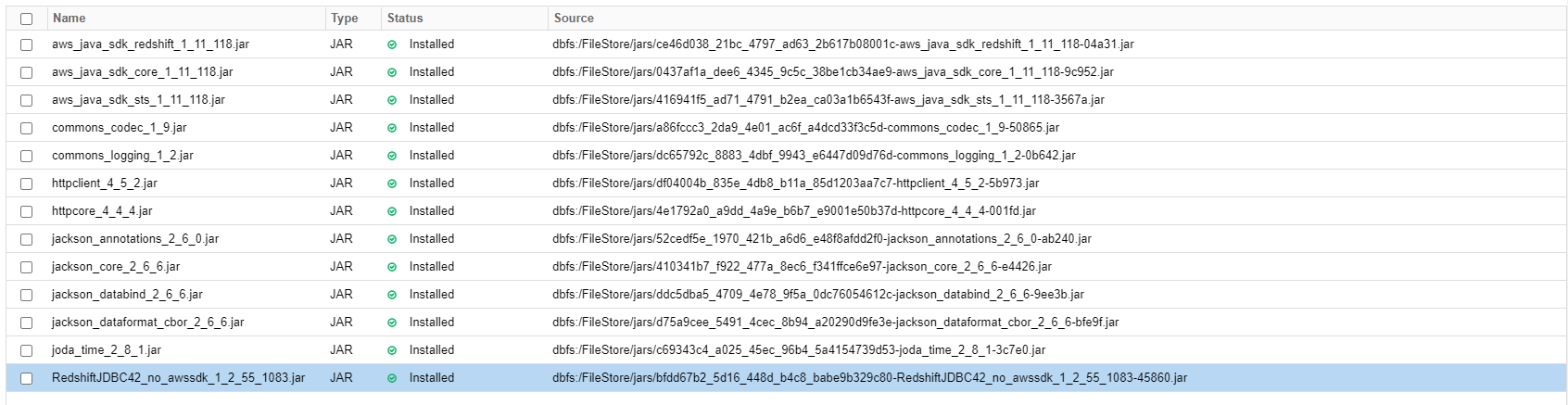
The final code will be on my GitHub.