I'm trying to create a scatter plot of two data, but I don't know how to specify my sorted result to the plot.
The procedure is like this:
- Read "data_to_be_chosen.csv"
- Read "data_to_be_plotted.csv"
- Sort "data_to_be_chosen.csv" to find the two topmost values (and their names)
- Find the corresponding names/columns in "data_to_be_plotted.csv"
- Show the scatter plot of the two
I have a problem at the 5th step.
Let's assume that Column C and Column A have the two topmost values.
If I manually set the data to the plot, it would be:
plot(plotted$C, plotted$A)
However, I'd like to have it done automatically, depending on the sorted order.
I thought the following code would work:
plot(plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1])],
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2])])
But, this gives me an error:
Error in stripchart.default(x1, ...) : invalid plotting method
I also tried these, but they don't work either:
plot(names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
plot(colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
Is there any way to set the sorted result to this plot?
I have no more ideas.
My R version is 4.1.2 (The latest version).
Here's my data:
data_to_be_chosen.csv
A,B,C
2.044281,0.757232,2.188617
data_to_be_plotted.csv
A,B,C
0.34503,-0.38781,-0.3506
0.351566,-0.3901,-0.35244
0.351817,-0.39144,-0.35435
0.351222,-0.39138,-0.35394
0.351222,-0.39113,-0.35366
0.350753,-0.39088,-0.35291
0.350628,-0.39041,-0.3531
0.349127,-0.3881,-0.3511
0.346125,-0.38675,-0.34969
0.346594,-0.38719,-0.34963
Here's my code:
plotted <- read.csv("data_to_be_plotted.csv")
chosen <- read.csv("data_to_be_chosen.csv")
chosen_list <- list(chosen=chosen)
sort(chosen_list$chosen[1,], decreasing=TRUE)[1:2]
names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1:2])
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1:2])]
# Correlation can be calculated with the above data frame
cor(plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1])],
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2])])
# What I want is this plot ... except manually specifying C or A
plot(plotted$C, plotted$A)
# The above data frame can NOT be used to plot / Issues "invalid plotting method"
plot(plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1])],
plotted[names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2])])
# I also tried, but no luck:
plot(names(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
names(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
plot(colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[1]),
colnames(sort(chosen_list$chosen[1,], decreasing=TRUE)[2]))
CodePudding user response:
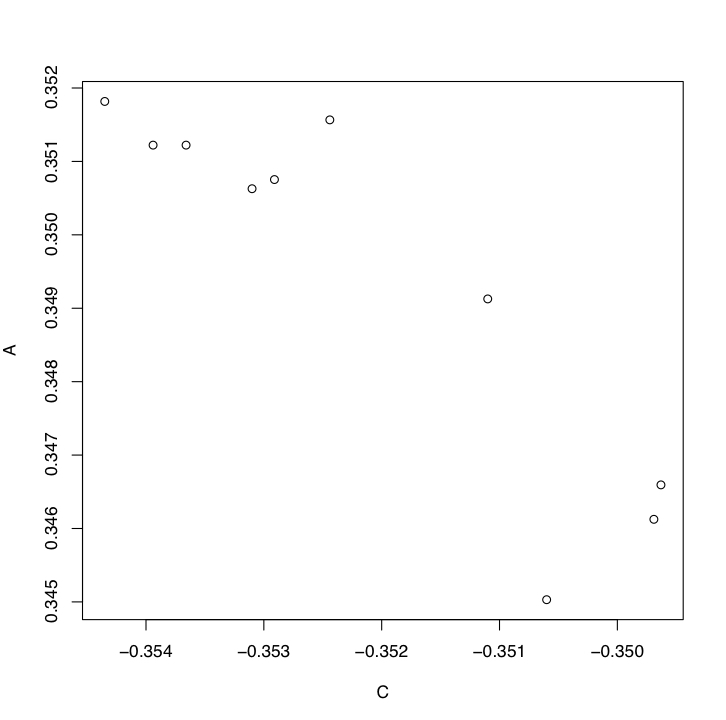
You can coerce the single-row “data_to_be_chosen” df to a named vector using unlist; then sort, get the first two names, and use these to index into “data_to_be_plotted”:
chosen_vec <- unlist(chosen)
plot(plotted[names(sort(chosen_vec, decreasing = TRUE)[1:2])])
CodePudding user response:
The problem, is just that subsetting one row gives a "data.frame" object instead of a "numeric" vector, what you probably expect. You can check that with class().
class(chosen_list$chosen[1,])
# [1] "data.frame"
The solution is to unlist it.
class(unlist(chosen_list$chosen[1,]))
# [1] "numeric"
In the following make use of creating objects instead of repeating code.
(x <- sort(unlist(chosen_list$chosen[1,]), decreasing=TRUE)[1:2])
# C A
# 2.188617 2.044281
(nx <- names(x))
# [1] "C" "A"
(p_df <- plotted[nx])
# C A
# 1 -0.35060 0.345030
# 2 -0.35244 0.351566
# 3 -0.35435 0.351817
# 4 -0.35394 0.351222
# 5 -0.35366 0.351222
# 6 -0.35291 0.350753
# 7 -0.35310 0.350628
# 8 -0.35110 0.349127
# 9 -0.34969 0.346125
# 10 -0.34963 0.346594
To get the correlation of two vectors of a data frame as a single value, we probably want [, j], since a data frame has two dimensions.
cor(p_df[, 1], p_df[, 2])
# [1] -0.9029339
Check (similar to above):
class(cor(p_df[1], p_df[2]))
# [1] "matrix" "array"
class(cor(p_df[, 1], p_df[, 2]))
# [1] "numeric"
I recommend you to update your knowledge about 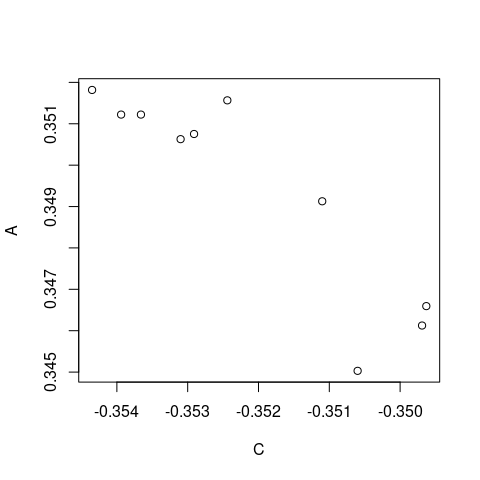
Data:
plotted <- structure(list(A = c(0.34503, 0.351566, 0.351817, 0.351222, 0.351222,
0.350753, 0.350628, 0.349127, 0.346125, 0.346594), B = c(-0.38781,
-0.3901, -0.39144, -0.39138, -0.39113, -0.39088, -0.39041, -0.3881,
-0.38675, -0.38719), C = c(-0.3506, -0.35244, -0.35435, -0.35394,
-0.35366, -0.35291, -0.3531, -0.3511, -0.34969, -0.34963)), class = "data.frame", row.names = c(NA,
-10L))
chosen <- structure(list(A = 2.044281, B = 0.757232, C = 2.188617), class = "data.frame", row.names = c(NA,
-1L))
chosen_list <- list(chosen=chosen)