I'm having a timeseries dataset like the following:
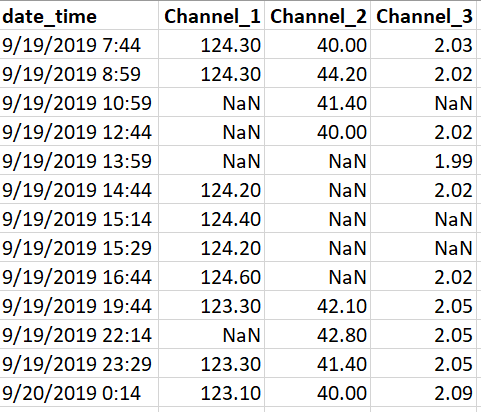
As seen, there are three columns for channel values paired against the same set of timestamps. Each channel has sets of NaN values.
My objective is to create a summary of these NaN values as follows:
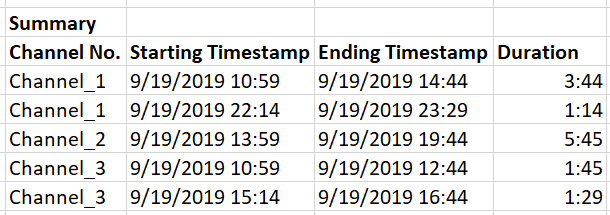
My approach (inefficient): Create a for loop to go across each channel column first, and then another nested for loop to go across each row of the channel. Then when it stumbles across NaN value sets, it can register the start timestamp, end timestamp and duration in the form of individual rows (or lists), which I can eventually stack together as the final output.
But my logic seems pretty inefficient and slow especially considering that my original dataset has 200 channel columns and 10k rows. I'm sure there should be a better approach than this in Python.
Can anyone please help me out with an appropriate way to deal with this - using Pandas in Python?
CodePudding user response:
Use DataFrame.melt for reshape DataFrame, then filter consecutive groups by misisng values and next value after missing and create new DataFrame by aggregation min with max values:
df['date_time'] = pd.to_datetime(df['date_time'])
df1 = df.melt('date_time', var_name='Channel No.')
m = df1['value'].shift(fill_value=False).notna() #
mask = df1['value'].isna() | ~m
df1 = (df1.groupby([m.cumsum()[mask], 'Channel No.'])
.agg(Starting_Timestamp = ('date_time','min'),
Ending_Timestamp = ('date_time','max'))
.assign(Duration = lambda x: x['Ending_Timestamp'].sub(x['Starting_Timestamp']))
.droplevel(0)
.reset_index()
)
print (df1)
Channel No. Starting_Timestamp Ending_Timestamp Duration
0 Channel_1 2019-09-19 10:59:00 2019-09-19 14:44:00 0 days 03:45:00
1 Channel_1 2019-09-19 22:14:00 2019-09-19 23:29:00 0 days 01:15:00
2 Channel_2 2019-09-19 13:59:00 2019-09-19 19:44:00 0 days 05:45:00
3 Channel_3 2019-09-19 10:59:00 2019-09-19 12:44:00 0 days 01:45:00
4 Channel_3 2019-09-19 15:14:00 2019-09-19 16:44:00 0 days 01:30:00
CodePudding user response:
Use:
inds = df[df['g'].isna()].index.to_list()
gs = []
s = 0
for i, x in enumerate(inds):
if i<len(inds)-1:
if x 1!=inds[i 1]:
gs.append(inds[s:i 1])
s = i 1
else:
gs.append(inds[s:i 1])
ses = []
for g in gs:
ses.append([df.iloc[g[0]]['date'], df.iloc[g[-1] 1]['date']])
res = pd.DataFrame(ses, columns = ['st', 'et'])
res['d'] = res['et']-res['st']
And a more efficient solution:
import pandas as pd
import numpy as np
df = pd.DataFrame({'date':pd.date_range('2021-01-01', '2021-12-01', 12), 'g':range(12)})
df['g'].loc[0:3]=np.nan
df['g'].loc[5:7]=np.nan
inds = df[df['g'].isna().astype(int).diff()==-1].index 1
pd.DataFrame([(x.iloc[0]['date'], x.iloc[-1]['date']) for x in np.array_split(df, inds) if np.isnan(x['g'].iloc[0])])