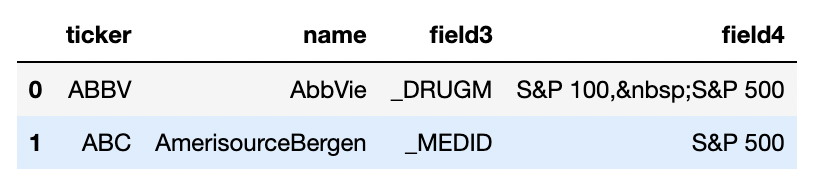
I'm trying to take the output from this code into a pandas dataframe. I'm really only trying to pull the first part of the output which is the stock symbols,company name, field3, field4. The output has a lot of other data I'm not interested in but it's giving me everything. Could someone help me to put this into a dataframe if possible?
The current output is in this format
["ABBV","AbbVie","_DRUGM","S&P 100, S&P 500"],["ABC","AmerisourceBergen","_MEDID","S&P 500"],
Desired Output

Full Code
import requests
import pandas as pd
import requests
url = "https://www.stockrover.com/build/production/Research/tail.js?1644930560"
payload={}
headers = {}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
CodePudding user response:
Use a dictionary to store the data from your tuple of lists, then create a DataFrame based on that dictionary. In my solution below, I omit the 'ID' field because the index of the DataFrame serves the same purpose.
import pandas as pd
# Store the data you're getting from requests
data = ["ABBV","AbbVie","_DRUGM","S&P 100, S&P 500"],["ABC","AmerisourceBergen","_MEDID","S&P 500"]
# Create an empty dictionary with relevant keys
dic = {
"Ticker": [],
"Name": [],
"Field3": [],
"Field4": []
}
# Append data to the dictionary for every list in your `response`
for pos, lst in enumerate(data):
dic['Ticker'].append(lst[0])
dic['Name'].append(lst[1])
dic['Field3'].append(lst[2])
dic['Field4'].append(lst[3])
# Create a DataFrame from the dictionary above
df = pd.DataFrame(dic)
The resulting dictionary looks like so.
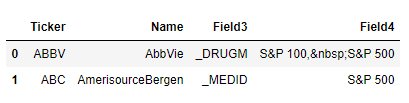
Edit: A More Efficient Approach
In my solution above, I manually called the list form of each key in the dic dictionary. Using zip we can streamline the process and have it work for any length response and any changes you make to the labels of the dictionary.
The only caveat to this method is that you have to make sure the order of keys in the dictionary lines up with the data in each list in your response. For example, if Ticker is the first dictionary key, the ticker must be the first item in the list resulted from your response. This was true for the first solution, too, however.
new_dic = {
"Ticker": [],
"Name": [],
"Field3": [],
"Field4": []
}
for pos, lst in enumerate(data): # Iterate position and list
for key, item in zip(new_dic, data[pos]): # Iterate key and item in list
new_dic[key].append(item) # Append to each key the item in list
df = pd.DataFrame(new_dic)
The result is identical to the method above:

Edit (even better!)
I'm coming back to this after learning from a commenter that pd.DataFrame() can input two-dimensional array data and output a DataFrame. This would streamline the entire process several times over:
import pandas as pd
# Store the data you're getting from requests
data = ["ABBV","AbbVie","_DRUGM","S&P 100, S&P 500"],["ABC","AmerisourceBergen","_MEDID","S&P 500"]
# Define columns
columns = ['ticker', 'name', 'field3', 'field4']
df = pd.DataFrame(data, columns = columns)
The result (same as first two):