My csv looks like this:
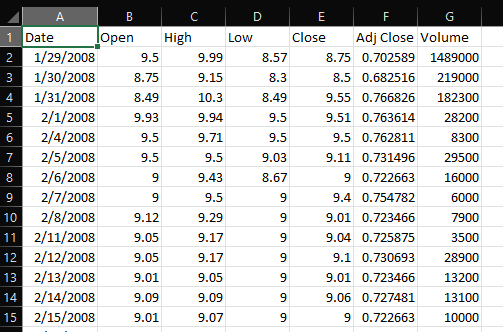
I am reading multiple csv files in the list, with first column "Date" as index and parsing the dates as well:
all_max = []
for f in max_files:
data_instance = pd.read_csv(os.path.join(max_path, f), index_col=0, parse_dates=['Date'])
all_max.append(data_instance)
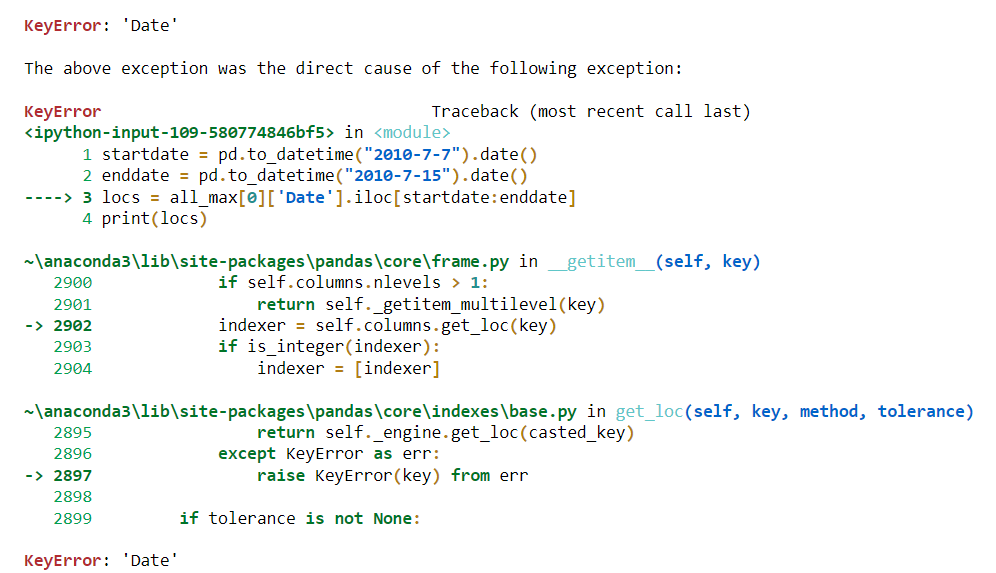
I want to file the records in range of startdate and enddate.
startdate = pd.to_datetime("2010-7-7").date()
enddate = pd.to_datetime("2010-7-15").date()
locs = all_max[0]['Date'].iloc[startdate:enddate]
print(locs)
But I get an ERROR
CodePudding user response:
Your dates are the index, so you're getting a key error when trying to select using the "Date" column that doesn't exist. Here's a toy example of how you can select using an index.
import pandas as pd
df = pd.DataFrame({'Date': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04', '2022-01-05'],
'this': [5,2,2,5,5],
'that': [3,3,3,3,3]},
)
df.to_csv('dates.csv', index=False)
dates = pd.read_csv('dates.csv', index_col=0, parse_dates=['Date'])
dates = dates.loc[(dates.index > '2022-01-01') & (dates.index <= '2022-01-03')]
Output:
this that
Date
2022-01-02 2 3
2022-01-03 2 3
CodePudding user response:
iloc is for integer indexing—i.e. by row position.
Try using loc instead. Also note that pandas accepts dates as strings and does the necessary conversion for you.
startdate = "2010-7-7"
enddate = "2010-7-15"
selection = all_max[0].loc[startdate:enddate]
dates = selection.index