I am trying to iterate through every row of the first column of the following output.
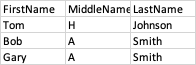
Assume table Employees has 3 columns: FirstName, MiddleName, LastName
table1=spark.sql("Select * from Employees")
CodePudding user response:
If your table is small enough, then collect would be the best table1.select('FirstName').collect()
However, keep in mind that collect is not scalable, as it uses a single machine instead of distributing the workload to workers.