I have this sample pandas dataframe:
data = {'type': ['student', 'student', 'student','student','student','student'],
'student_id': ['12345', '12345', '12345','12345','21354','21354'],
'student_name': ['Jane', 'Jane','Jane','Jane','Joe','Joe'],
'deadline': ['2021-01-01', '2021-01-01','2022-02-01','2022-02-01','2021-01-01','2021-01-01'],
'subject_code': ['110', '112','110','116','110','116'],
'subject_description': ['Math', 'Science','Math','PE','Math','PE'],
'subject_grade': ['90.1', '92.2','88.6','90.1','90.2','89.4']
}
df = pd.DataFrame(data)
df
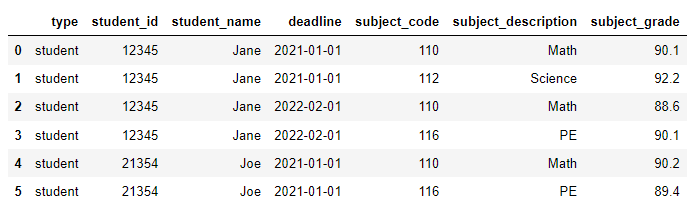
Question: Is it possible to transform this dataframe into a specific JSON Structure like below?
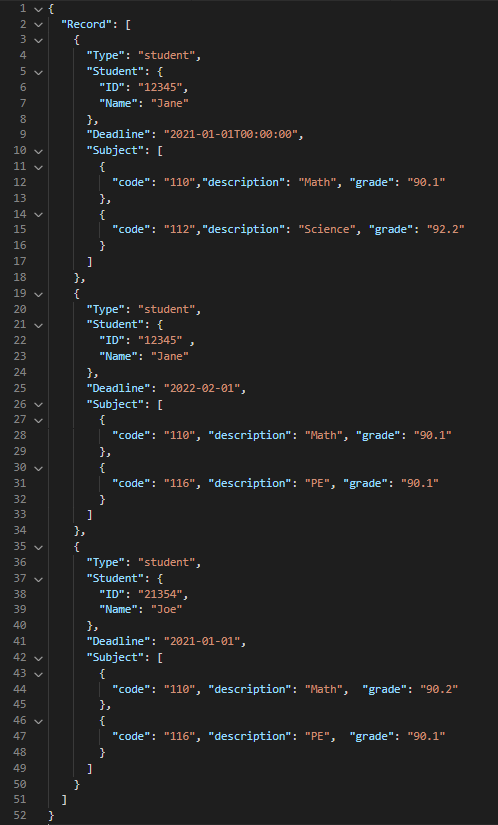
I tried using groupby dataframe but I still can't make a structure like above. Is this achievable? Or do I need to restructure my table?
CodePudding user response:
Nested dictionaries from a dataframe can be tricky. This should work, but it's not quite as simple/clean as I'd like.
# Change columns to MultiIndex (splitting on '_')
df.columns = pd.MultiIndex.from_tuples(tuple(x.split('_')) for x in df.columns)
# Get initial dictionary from columns with only one level
data_dict = df[[col for col in df.columns if pd.isna(col[1])]].droplevel(-1, axis=1).to_dict(orient='index')
# Prepare a slice of the dataframe with the remaining 2-level columns
double_level = df[[col for col in df.columns if pd.notna(col[1])]]
# loop through the "double levels" and update starting dictionary
for top_level in list(set(x[0] for x in double_level.columns)):
temp = {k: {top_level: v} for k,v in double_level.xs(top_level, axis=1).to_dict(orient='index').items()}
for key in data_dict:
data_dict[key] = {**data_dict[key], **temp[key]}
# create final list of records
records = list(data_dict.values())
Here's the output.
print(json.dumps(records, indent=4))
[
{
"type": "student",
"deadline": "2021-01-01",
"student": {
"id": "12345",
"name": "Jane"
},
"subject": {
"code": "110",
"description": "Math",
"grade": "90.1"
}
},
{
"type": "student",
"deadline": "2021-01-01",
"student": {
"id": "12345",
"name": "Jane"
},
"subject": {
"code": "112",
"description": "Science",
"grade": "92.2"
}
},
{
"type": "student",
"deadline": "2022-02-01",
"student": {
"id": "12345",
"name": "Jane"
},
"subject": {
"code": "110",
"description": "Math",
"grade": "88.6"
}
},
{
"type": "student",
"deadline": "2022-02-01",
"student": {
"id": "12345",
"name": "Jane"
},
"subject": {
"code": "116",
"description": "PE",
"grade": "90.1"
}
},
{
"type": "student",
"deadline": "2021-01-01",
"student": {
"id": "21354",
"name": "Joe"
},
"subject": {
"code": "110",
"description": "Math",
"grade": "90.2"
}
},
{
"type": "student",
"deadline": "2021-01-01",
"student": {
"id": "21354",
"name": "Joe"
},
"subject": {
"code": "116",
"description": "PE",
"grade": "89.4"
}
}
]
CodePudding user response:
You can try using js = df.to_json(orient = 'records') which is the closest possible
Please find the JSON structure using the above line [1]: https://i.stack.imgur.com/J3JjS.png
{kind=link}
Probably you can try restructuring the JSON according to your needs