I've been trying to scrape some info for personal use from a website. It works nice, no errors, but I found out it somehow can't see email addresses from second half of the site. Code I'm using:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://rejestradwokatow.pl/adwokat/abramowicz-joanna-49486')
soup = BeautifulSoup(page.content, "html.parser")
kancelaria = [x.strip() for x in soup.find(
'div', class_='mb_tab_content special_one').find_all('div')[::2][0].text.split('\n') if x != ''][1:]
with result:
>>> kancelaria
['Kancelaria Adwokacka', 'Chlebnicka 48/51', '80-830 Gdańsk', '', 'Stacjonarny/Fax: 583054010', 'Email: [email\xa0protected]']
Please take notice in last element: 'Email: [email\xa0protected]'. I believe it has something to do with reCAPTCHA mechanism implemented in the website, but I have no idea how to go around it. Interesting - emails from first half of the site are visible for my program and can be scraped. Anh thoughts?
EDIT:
I'm reffering to the lower part of the page:
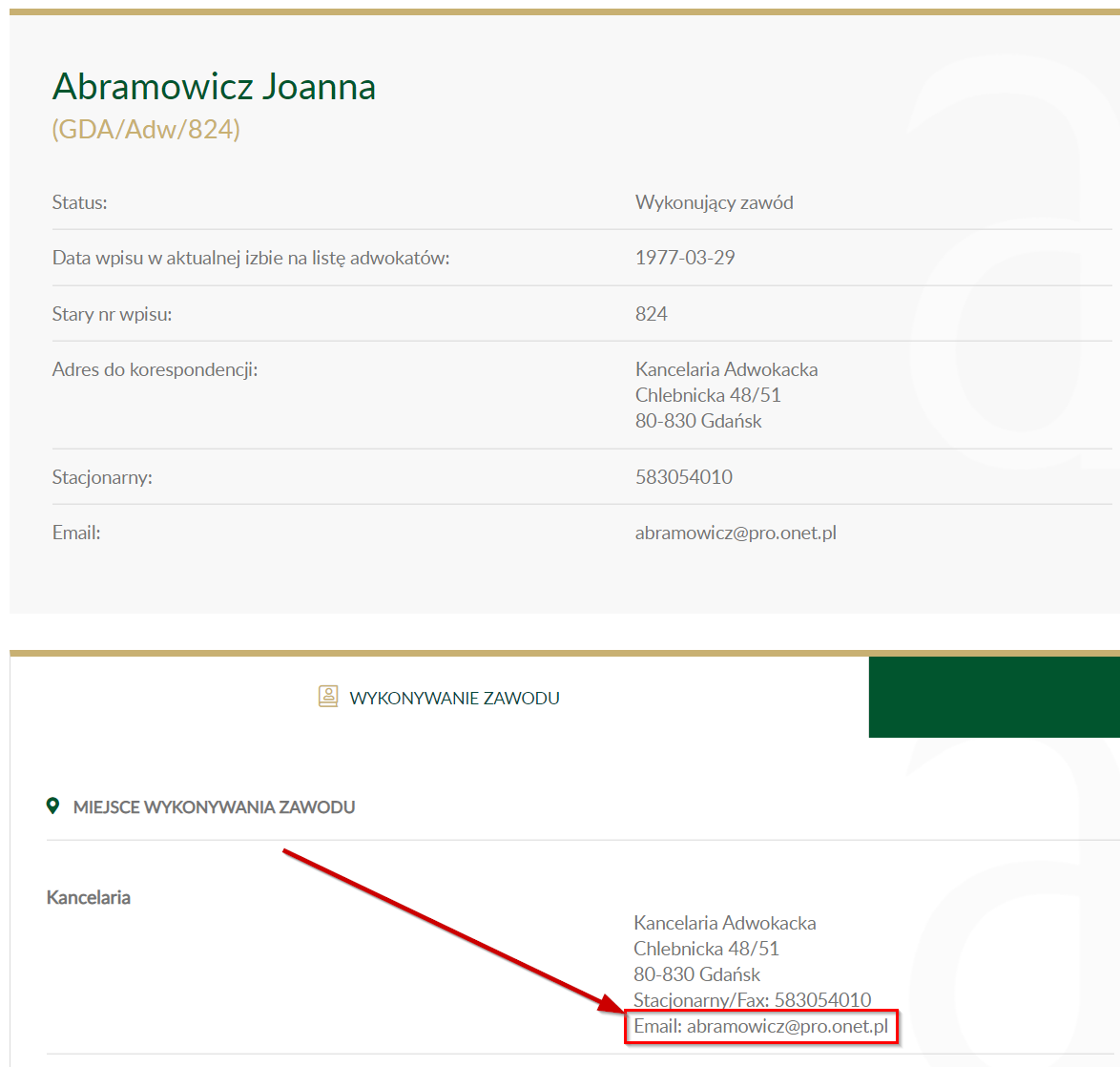
CodePudding user response:
To get just emails, enter the following:
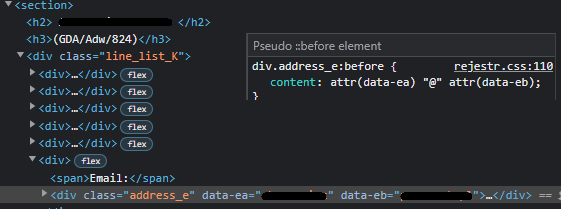
email_1st_part = soup.find('div', class_="address_e").get('data-ea')
email_2nd_part = soup.find('div', class_="address_e").get('data-eb')
email = email_1st_part '@' email_2nd_part
Full Code:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://rejestradwokatow.pl/adwokat/abramowicz-joanna-49486')
soup = BeautifulSoup(page.content, "html.parser")
email_1st_part = soup.find('div', class_="address_e").get('data-ea')
email_2nd_part = soup.find('div', class_="address_e").get('data-eb')
email = email_1st_part '@' email_2nd_part
Result:
print(email)
'[email protected]'
CodePudding user response:
The email is generated with CSS. You have to extract attribute values in div data-ea and data-eb and join with @
name = soup.find('div', class_="address_e").get('data-ea')
domain = soup.find('div', class_="address_e").get('data-eb')
email = f'{name}@{domain}'
CodePudding user response:
I'm going to add another answer to this: That one is created by Javascript, and you may test it using Selenium. The code is provided below.
from selenium import webdriver
import chromedriver_autoinstaller
# auto install chromedriver
chromedriver = chromedriver_autoinstaller.install()
# driver define and lunch
driver = webdriver.Chrome(chromedriver)
driver.maximize_window()
# Go to website and get email
url = 'https://rejestradwokatow.pl/adwokat/artymiak-grzegorz-46439'
driver.get(url)
email_text = driver.find_element_by_xpath('//div[@]/div[@]').text.split('Email: ')
email = email_text[-1]
print(email)
[email protected]