In statistics
if you predict a value 1 and the original value was 1 then this is called True Positive (TP)
if the prediction is 0 and the original value was 1 then it is False Negative (FN)
if the prediction is 1 and the original value was 0 then it is False Positive (FP)
if the prediction is 0 and the original value was 0 then it is True Negative (TN)
F1 score is a method to measure the relation between 2 datasets
Which is calculated like this

I have a file that has the results of 1000 predictions each value is either 0 or 1
that looks like this
Label 0 1 2 .... 0 1 2 ...
--------------------------------------------------
0 0 1 0 1 1
1 0 0 1 0 1
0 1 1 0 0 0
0 0 1 0 1 1
1 0 0 0 0 0
1 0 1 0 1 1
0 0 1 1 0 1
1 1 1 1 1 0
0 1 0 1 0 1
1 1 0 0 0 1
1 0 0 0 1 0
1 1 0 1 1 1
0 1 1 1 0 1
0 0 1 0 1 1
0 1 0 1 0 0
1 1 0 0 1 0
0 1 1 1 1 1
0 0 0 1 0 0
0 0 1 0 1 1
0 1 1 1 0 0
The only way I can think of having a 1000 new columns to detect TP and another to detect FP and anorger 1000 for TN and another 1000 for FN
where each has this equation =if(AND(B6=NB6,B6=1), 1, 0) for TP and so on
this is not a good solution
is there a faster easier way to get F1 score for each one of these columns or even better F1 score micro and macro for all?
CodePudding user response:
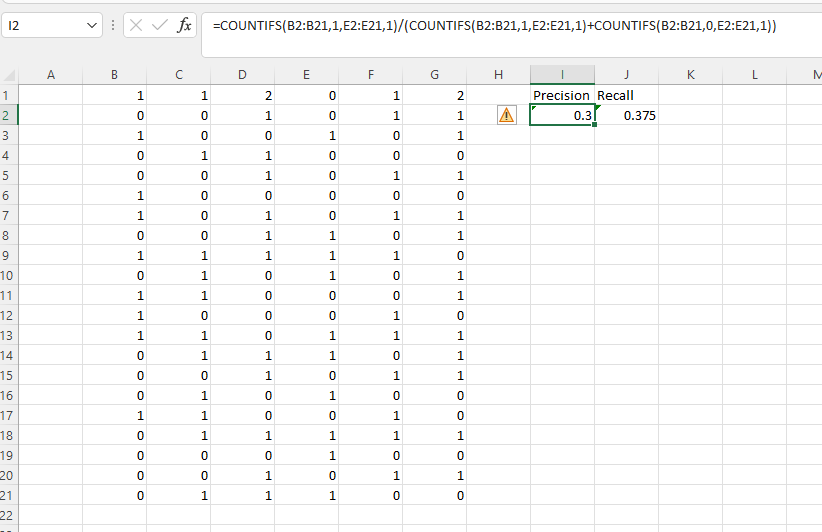
I'm not going to finish this tonight, but I think the formulas for columns B and E of the test data would be
Precision:
=COUNTIFS(B2:B21,1,E2:E21,1)/(COUNTIFS(B2:B21,1,E2:E21,1) COUNTIFS(B2:B21,0,E2:E21,1))
Recall
=COUNTIFS(B2:B21,1,E2:E21,1)/(COUNTIFS(B2:B21,1,E2:E21,1) COUNTIFS(B2:B21,1,E2:E21,0))
and you can get the others in the same way