I want to get the data only from category using Xpath
Page link: 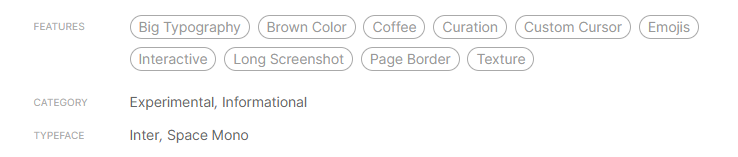
This is my code:
from scrapy.http import Request
import scrapy
class PushpaSpider(scrapy.Spider):
name = 'pushpa'
start_urls = ['https://onepagelove.com/inspiration']
def parse(self, response):
books = response.xpath("//div[@class='thumb-image']//a//@href").extract()
for book in books:
absolute_url = response.urljoin(book)
yield Request(absolute_url, callback=self.parse_book)
def parse_book(self, response):
coordinate = response.xpath("//div[@class='inspo-links']//span[2]//text()").getall()
coordinate = [i.strip() for i in coordinate]
# remove empty strings:s
coordinate = [i for i in coordinate if i]
yield{
'category':coordinate
}
CodePudding user response:
The website has multiple inspo-links inside the header, thus you are extracting from many different types of data.
Xpath version:
def parse_book(self, response):
xpath_coordinate = response.xpath(
"//span[@class='link-list']")[1].xpath("a/text()").extract()
yield {
'category': xpath_coordinate
}
CSS version:
def parse_book(self, response):
content = response.css('div.review-content')
coordinate = header.css("span.link-list")[1].css("a::text").extract()
yield {
'category': coordinate
}
This snippet here will provide you only the categories.
On your image example, it would give you ["Experimental", "Informational"]
Note: On your main method you are getting an extra link for something that is not a book and doesn't have categories, scrapy automatically handles the errors, so you still get the complete output.
Here is an Xpath example that brings all 3 types of data from the image:
def parse_book(self, response):
xpath_coordinate = response.xpath(
"//span[@class='link-list']")
features = xpath_coordinate[0].xpath("a/text()").extract()
category = xpath_coordinate[1].xpath("a/text()").extract()
typeface = xpath_coordinate[2].xpath("a/text()").extract()
yield {
'feature': features,
'category': category,
'typeface': typeface
}