I have the below dataframe with many columns- 2016_x, 2016_y, 2017_x, etc,
where x represents my actual values and y represents the forecast values.
How would I compute the mean squared error (MSE) row-wise to see it for different fruits. Here is the below code-
import pandas as pd
s={'Fruits':['Apple','Mango'],'2016_x':[2,3],'2017_x':[4,5],'2018_x':[12,13],'2016_y':[3,4],'2017_y':[3,4],'2018_y':[12,13]}
p=pd.DataFrame(data=s)
This is how the dataframe looks like-
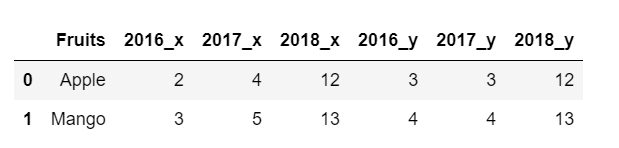
The desired output should show MSE of Apple and Mango, i.e. row by row.
MSE should take difference of x and y values of the year.
Basically, I need the total MSE for Apple and Mango respectively.
I know MSE can be calculated as-
MSE = np.mean((p['x'] - p['y'])**2, axis=1)
But how would I calculate for this type of data frame?
CodePudding user response:
Set the index to Fruits and transform the columns into a MultiIndex of (x/y, year):
p = p.set_index('Fruits')
p.columns = p.columns.str.split('_', expand=True)
p = p.swaplevel(axis=1)
# x y
# 2016 2017 2018 2016 2017 2018
# Fruits
# Apple 2 4 12 3 3 12
# Mango 3 5 13 4 4 13
Then the MSE arithmetic can be vectorized:
mse = p['x'].sub(p['y']).pow(2).mean(axis=1)
# Fruits
# Apple 0.666667
# Mango 0.666667
# dtype: float64
Note that chaining sub and pow is just a cleaner way of applying - and ** on columns:
mse = ((p['x'] - p['y']) ** 2).mean(axis=1)