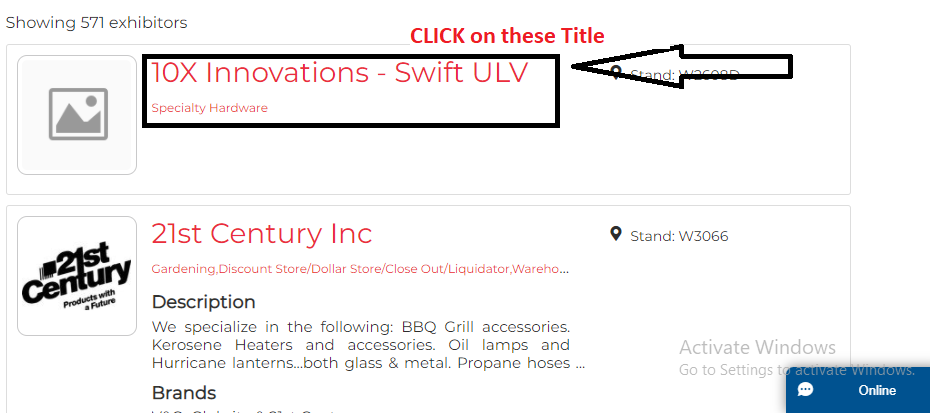
For example this is the main page link
This is code
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
from time import sleep
PATH="C:\Program Files (x86)\chromedriver.exe"
driver =webdriver.Chrome(PATH)
driver.get('https://www.nationalhardwareshow.com/en-us/attend/exhibitor-list.html')
data = []
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button#onetrust-accept-btn-handler"))).click()
hrefs = [my_elem.get_attribute("href") for my_elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.XPATH, "//h3[@class='text-center-mobile wrap-word']//ancestor::a[1]")))[:5]]
windows_before = driver.current_window_handle
for href in hrefs:
driver.execute_script("window.open('" href "');")
WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2))
windows_after = driver.window_handles
new_window = [x for x in windows_after if x != windows_before][0]
driver.switch_to.window(new_window)
data.append(WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, "//h1[@class='wrap-word']"))).text)
driver.close()
driver.switch_to.window(windows_before)
print(data)
CodePudding user response:
Your current problem is invalid XPath //div[contains(@class,'company-info']//h3)] - wrong parentheses usage. You need to use //div[contains(@class,'company-info')]//h3 instead.
However, if you want to scrape data from each company entry on page then your clicking links approach is not good.
Try to implement the following:
get
hrefattribute of every link. Since not all links initially displayed on page you need to trigger all possible XHRs, so createcountvariable to get current links count and do in while loop:- execute send
ENDhardkey to scroll page down - try to wait until current links count >
count. If True - re-definecountwith new value. If Exception - break the loop (there are no more links remain to load) - get
hrefof all link nodes//div[@]//a
- execute send
in
forloop navigate to each link withdriver.get(<URL>)scrape data
CodePudding user response:
With in the 2022 EXHIBITOR LIST webpage to click() on each link to scrape you can collect the href attributes and open them in the adjascent tab as follows:
Code Block (sample for first 5 entries):
driver.get('https://www.nationalhardwareshow.com/en-us/attend/exhibitor-list.html') data = [] WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button#onetrust-accept-btn-handler"))).click() hrefs = [my_elem.get_attribute("href") for my_elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.XPATH, "//h3[@class='text-center-mobile wrap-word']//ancestor::a[1]")))[:5]] windows_before = driver.current_window_handle for href in hrefs: driver.execute_script("window.open('" href "');") WebDriverWait(driver, 20).until(EC.number_of_windows_to_be(2)) windows_after = driver.window_handles new_window = [x for x in windows_after if x != windows_before][0] driver.switch_to.window(new_window) data.append(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//h1[@class='wrap-word']"))).text) driver.close() driver.switch_to.window(windows_before) print(data)Console Output:
['10X Innovations - Swift ULV', '21st Century Inc', '3V Snap Ring LLC.', 'A-ipower Corp', 'A.A.C. Forearm Forklift Inc']