I try to crawler a small table data from 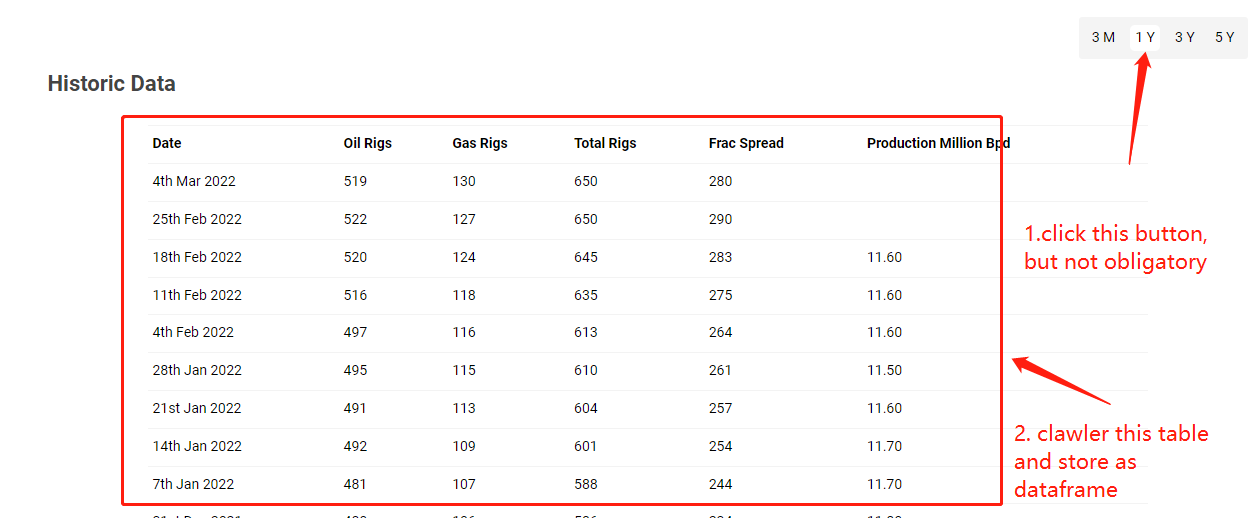
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://oilprice.com/rig-count'
# html = urllib.request.urlopen(url)
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
contents = soup.find_all('div', {'class': 'info_table'})
print(contents[0].children)
rows = []
for child in contents[0].children:
row = []
for td in child:
print(td) # not work after this line
try:
row.append(td.text.replace('\n', ''))
except:
continue
if len(row) > 0:
rows.append(row)
df = pd.DataFrame(rows[1:], columns=rows[0])
print(df)
Since the output of contents is quite large html data, so I don't know how to correctly extract them and save as dataframe. Could someone share an answer or give me some tips? Thanks.
CodePudding user response:
You can use:
table = soup.find('div', {'class': 'info_table'})
data = [[cell.text.strip() for cell in row.find_all('div')]
for row in table.find_all('div', recursive=False)]
df = pd.DataFrame(data[1:], columns=data[0])
Output:
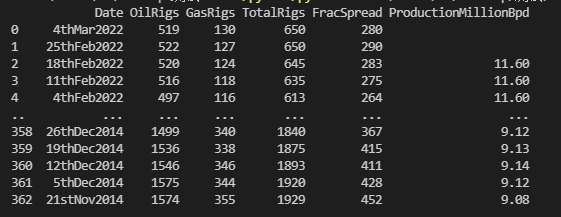
>>> df
Date Oil Rigs Gas Rigs Total Rigs Frac Spread Production Million Bpd
0 4th Mar 2022 519 130 650 280
1 25th Feb 2022 522 127 650 290
2 18th Feb 2022 520 124 645 283 11.60
3 11th Feb 2022 516 118 635 275 11.60
4 4th Feb 2022 497 116 613 264 11.60
.. ... ... ... ... ... ...
358 26th Dec 2014 1499 340 1840 367 9.12
359 19th Dec 2014 1536 338 1875 415 9.13
360 12th Dec 2014 1546 346 1893 411 9.14
361 5th Dec 2014 1575 344 1920 428 9.12
362 21st Nov 2014 1574 355 1929 452 9.08
[363 rows x 6 columns]
Update
A lazy solution to let Pandas guess the datatype is to convert your data to csv:
import io
table = soup.find('div', {'class': 'info_table'})
data = ['\t'.join(cell.text.strip() for cell in row.find_all('div'))
for row in table.find_all('div', recursive=False)]
buf = io.StringIO()
buf.writelines('\n'.join(data))
buf.seek(0)
df = pd.read_csv(buf, sep='\t', parse_dates=['Date'])
Output:
>>> df
Date Oil Rigs Gas Rigs Total Rigs Frac Spread Production Million Bpd
0 2022-03-04 519 130 650 280 NaN
1 2022-02-25 522 127 650 290 NaN
2 2022-02-18 520 124 645 283 11.60
3 2022-02-11 516 118 635 275 11.60
4 2022-02-04 497 116 613 264 11.60
.. ... ... ... ... ... ...
358 2014-12-26 1499 340 1840 367 9.12
359 2014-12-19 1536 338 1875 415 9.13
360 2014-12-12 1546 346 1893 411 9.14
361 2014-12-05 1575 344 1920 428 9.12
362 2014-11-21 1574 355 1929 452 9.08
[363 rows x 6 columns]
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 363 entries, 0 to 362
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 363 non-null datetime64[ns]
1 Oil Rigs 363 non-null int64
2 Gas Rigs 363 non-null int64
3 Total Rigs 363 non-null int64
4 Frac Spread 363 non-null int64
5 Production Million Bpd 360 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(4)
memory usage: 17.1 KB
CodePudding user response:
The best answer must correspond to the smallest change, you just need to use re for reasonable matching:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import bs4
import re
url = 'https://oilprice.com/rig-count'
# html = urllib.request.urlopen(url)
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
contents = soup.find_all('div', {'class': 'info_table'})
rows = []
for child in contents[0].children:
row = []
for td in child:
if type(td) == bs4.element.Tag:
data = re.sub('\s','',re.findall('(<[/]?[a-zA-Z].*?>)([\s\S]*?)?(<[/]?[a-zA-Z].*?>)',str(td))[0][1])
row.append(data)
if row != []:
rows.append(row)
df = pd.DataFrame(rows[1:], columns=rows[0])
print(df)
CodePudding user response:
I apply list comprehension technique.
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = 'https://oilprice.com/rig-count'
req = requests.get(url).text
lst = []
soup = BeautifulSoup(req, 'lxml')
data = [x.get_text().replace('\t', '').replace('\n\n',' ').replace('\n','') for x in soup.select('div.info_table_holder div div.info_table_row')]
lst.extend(data)
df = pd.DataFrame(lst, columns=['Data'])
print(df)
Output:
0 4th Mar 2022 519 130 650 280
1 25th Feb 2022 522 127 650 290
2 18th Feb 2022 520 124 645 283 11.60
3 11th Feb 2022 516 118 635 275 11.60
4 4th Feb 2022 497 116 613 264 11.60
... ...
2007 4th Feb 2000 157 387 0 0 0 0
2008 28th Jan 2000 171 381 0 0 0 0
2009 21st Jan 2000 186 338 0 0 0 0
2010 14th Jan 2000 169 342 0 0 0 0
2011 7th Jan 2000 134 266 0 0 0 0
[2012 rows x 1 columns]