I have two dataframes (df1, df2), df1 contains the list of topics and df2 contains the topics in df1 with its cluster or group.
Here is a sample input dataframe:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'topics':['algebra', 'evolution', 'calculus', 'quantum', 'geometry', 'botany', 'physics', 'zoology']})
giving

df2 = pd.DataFrame({'topics':['algebra', 'calculus', 'geometry','evolution', 'botany', 'zoology', 'quantum', 'physics'],
'cluster':[0, 0, 0, 1, 1, 1, 2, 2]
})
giving
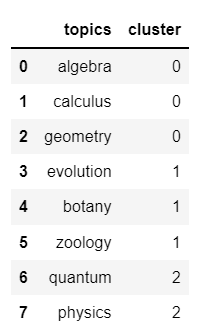
From the above dataframes, I need to create a final dataframe as below which has a matrix structure, (e.g. if the corresponding topic in the same cluster, assign 1, and otherwise 0)?
CodePudding user response:
Here's a vectorized solution that works:
s = df2.set_index('topics')['cluster']
new_df = pd.concat([s.eq(s[k]) for k in df1['topics']], axis=1).loc[df1['topics'].tolist()].astype(int).set_axis(df1['topics'], axis=1)
Output:
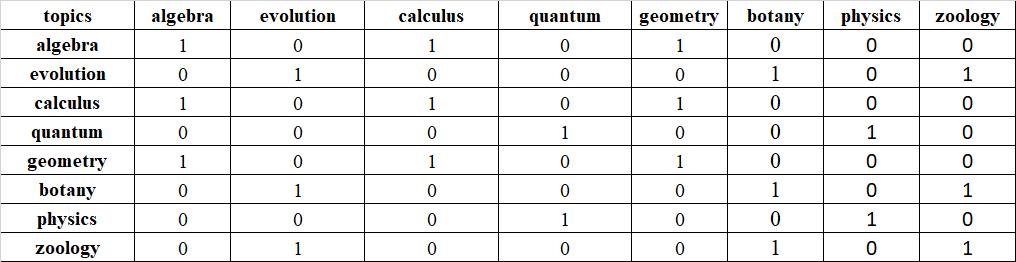
>>> new_df
topics algebra evolution calculus quantum geometry botany physics zoology
topics
algebra 1 0 1 0 1 0 0 0
evolution 0 1 0 0 0 1 0 1
calculus 1 0 1 0 1 0 0 0
quantum 0 0 0 1 0 0 1 0
geometry 1 0 1 0 1 0 0 0
botany 0 1 0 0 0 1 0 1
physics 0 0 0 1 0 0 1 0
zoology 0 1 0 0 0 1 0 1
CodePudding user response:
This is what I've come up with:
new_df = pd.DataFrame(index=df2.topics)
for _, row in df2.iterrows():
new_df[row.values[0]] = (df2.cluster == row.values[1]).astype(int).values