I'm trying to using concatenate with the to_timestamp() on a Apache Spark table and add a columns using the .withColumn function but it won't work.
The code is as follows:
DIM_WORK_ORDER.withColumn("LAST_MODIFICATION_DT", to_timestamp(concat(col('LAST_MOD_DATE'), lit(' '), col('LAST_MOD_TIME')), 'yyyyMMdd HHmmss'))
The result I would expect to see is something like
LAST_MODIFICATION_DT | WORK_ORDER
However, I'm getting the following result:
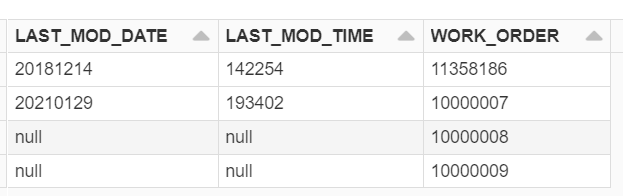
Some data to work with:
WORK_ORDER LAST_MOD_TIME 10000008 null 11358186 142254 10000007 193402 10000009 null
Any thoughts?
CodePudding user response:
as far as I know in spark dataframes are immutable. Hence,once you created dataframe it can't change.
%python
import pyspark
from pyspark.sql.functions import *
df = spark.read.option("header","true").csv("<input file path>")
df1 = df.withColumn("LAST_MODIFICATION_DT", to_timestamp(concat(col('LAST_MOD_DATE'), lit(' '), col('LAST_MOD_TIME')), 'yyyyMMdd HHmmss'))
display(df1)
I am getting below output as expected. If this is not what you expect, please provide more info
{kind=link}