I have this DataFrame:
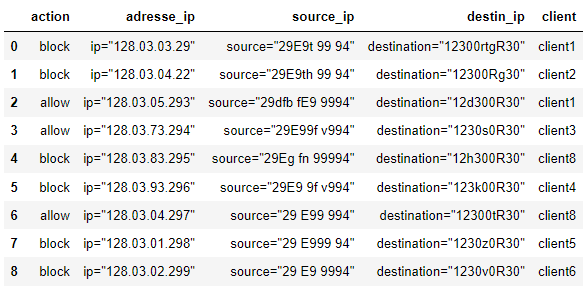
I would like to extract the lines where a client is at the same time in the Block action and the Alow action, so I want the lines: 0, 2, 4 and 6.
The solution with using index of rows, i can't use it because i have millions of lines.
CodePudding user response:
If action column is only contains, block and allow values, you can group your dataframe by client then, count the number of unique actions.
For example:
df.groupby("client")["action"].nunique()
If the extracted value is bigger than 1 than a specific client have the block and allow values at the same time.
CodePudding user response:
Use groupby, filter, and nunique:
indexes = df.groupby('client')['action'].filter(lambda x: x.nunique() >= 2).index
filtered = df.loc[indexes]
Output:
>>> indexes.tolist()
[0, 2, 4, 6]
>>> filtered
action client
0 block client1
2 allow client1
4 block client8
6 allow client8
CodePudding user response:
Here is an answer to your question which relies primarily on Python logic as opposed to Pandas logic.
It also includes a timeit performance comparison with a primarily Pandas based approach, which seems to show that the Python logic is more than 50 times faster for the chosen example with over 100,000 rows.
import pandas as pd
# Sample data
n = 100000
recordData = [['allow' if i < n // 2 else 'block', 'ip="128.03.03.29"', 'source="29E9t 99 94"', 'destination="12300rtgR30"', 'client' f'{i}'] for i in range(n)]
nDual = 20000
recordData = [['block'] recordData[i % n][1:] for i in range(1, 7 * nDual 1, 7)]
df = pd.DataFrame(data=recordData, columns=['action', 'adresse_ip', 'source_ip', 'destin_ip', 'client'])
print(f"Sample dataframe of length {len(df)}:")
print(df)
import timeit
# Selection
def foo(df):
blocks = {*list(df['client'][df['action'] == 'block'])}
allows = {*list(df['client'][df['action'] == 'allow'])}
duals = blocks & allows
rowsWithDuals = df[df['client'].apply(lambda x: x in duals)]
# Diagnostics
#print(f"blocks, allows, duals {len(blocks), len(allows), len(duals)}")
#print(len(df))
print(f"Number of rows for clients with dual actions: {len(rowsWithDuals)}")
return rowsWithDuals
print("\nPrimarily Python approach:")
t = timeit.timeit(lambda: foo(df), number = 1)
print(f"timeit: {t}")
def bar(df):
indexes = df.groupby('client')['action'].filter(lambda x: x.nunique() >= 2).index
filtered = df.loc[indexes]
print(f"Number of rows for clients with dual actions: {len(filtered)}")
return filtered
print("\nPrimarily Pandas approach:")
t = timeit.timeit(lambda: bar(df), number = 1)
print(f"timeit: {t}")
Outputs are:
Sample dataframe of length 120000:
action adresse_ip source_ip destin_ip client
0 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client0
1 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client1
2 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client2
3 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client3
4 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client4
... ... ... ... ... ...
119995 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39966
119996 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39973
119997 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39980
119998 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39987
119999 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39994
[120000 rows x 5 columns]
Primarily Python approach:
Number of rows for clients with dual actions: 25714
timeit: 0.04522189999988768
Primarily Pandas approach:
Number of rows for clients with dual actions: 25714
timeit: 3.1578059000021312
This would seem to suggest that using a primarily Python (not Pandas) approach is preferable for large datasets.