Lets take the following dataframe - Please ignore the output column for input. Output column is the expected output. It is difference in required dates
data = [
['Group1', 20211129, 'i', 0, 0],
['Group1', 20211202, 'r', 465852069, 3],
['Group1', 20211202, 'r', 465852070, 3],
['Group1', 20211206, 'i', 0, 0],
['Group1', 20211213, 'i', 0, 0],
['Group2', 20211129, 'i', 0, 0],
['Group2', 20211206, 'i', 0, 0],
['Group2', 20211210, 'r', 466486129, 11],
['Group2', 20211213, 'i', 0, 0],
['Group2', 20211227, 'i', 0, 0],
['Group2', 20220103, 'i', 0, 0],
['Group2', 20220104, 'r', 467650236, 22],
['Group2', 20220105, 'r', 467754363, 23]
]
data = pd.DataFrame(data, columns=['group', 'date', 'type', 'rid', 'output'])
data.date = pd.to_datetime(data.date, yearfirst=True, format='%Y%m%d')
data
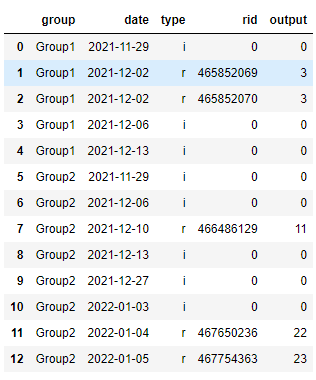
For each of the record of type r, I need to find farthest type i in upward direction in each of the group but should not cross type r. In the above example, for row 1, row 0 is the farthest i. for row 2, again row 0 is the farthest i. For row 7 which is Group, row 5 is the farthest i. For row 11, row 8 is the farthest i as we can not jump an r. For row 12, again row 8 is the farthest i. Final goal is to get the difference between the date fields corresponding to 'r' and the farthest 'i'.
I tried bfill on rid but to no success. I think there should be simpler way to achieve this.
CodePudding user response:
Idea is create groups by last r consecutive values and in custom function get minimal index of i rows:
#convert to datetimes
data['date'] = pd.to_datetime(data['date'], format='%Y%m%d')
#get Trues for last r consecutive values by chain with shifted value with compare i
g = data['type'].eq('r') & data['type'].shift(-1, fill_value='i').eq('i')
def f(x):
#get only i rows
m = x['type'].eq('i')
#filter date if exist else None and assign to new column
x['out'] = next(iter(x.loc[m, 'date']), None)
return x
#pas groups by column group and groups by last r with cumulative sum
data = data.groupby(['group', g.iloc[::-1].cumsum().iloc[::-1]]).apply(f)
#last get difference with set 0 if not match r
data['out'] = data['date'].sub(data['out']).dt.days.where(data['type'].eq('r'), 0)
print (data)
group date type rid out
0 Group1 2021-11-29 i 0 0
1 Group1 2021-12-02 r 465852069 3
2 Group1 2021-12-02 r 465852070 3
3 Group1 2021-12-06 i 0 0
4 Group1 2021-12-13 i 0 0
5 Group2 2021-11-29 i 0 0
6 Group2 2021-12-06 i 0 0
7 Group2 2021-12-10 r 466486129 11
8 Group2 2021-12-13 i 0 0
9 Group2 2021-12-27 i 0 0
10 Group2 2022-01-03 i 0 0
11 Group2 2022-01-04 r 467650236 22
12 Group2 2022-01-05 r 467754363 23