I need to slice a long format DataFrame by every x unique values for the purpose of visualizing. My actual dataset has ~ 90 variables for 20 individuals so I would like to split into 9 separate df's containing the entries for all 20 individuals for each variable.
I have created this simple example to help explain:
df = pd.DataFrame({'ID':[1,1,1,2,2,2,3,3,3,4,4,4],
'Period':[1,2,3,1,2,3,1,2,3,1,2,3,],
'Food':['Ham','Ham','Ham','Cheese','Cheese','Cheese','Egg','Egg','Egg','Bacon','Bacon','Bacon',]})
df
''' ******* PSUEDOCODE *******
df1 = unique entries [:2]
df2 = unique entries [2:4] '''
# desired outcome:
df1 = pd.DataFrame({'ID':[1,1,1,2,2,2,],
'Period':[1,2,3,1,2,3,],
'Food':['Ham','Ham','Ham','Cheese','Cheese','Cheese',]})
df2 = pd.DataFrame({'ID':[3,3,3,4,4,4],
'Period':[1,2,3,1,2,3,],
'Food':['Egg','Egg','Egg','Bacon','Bacon','Bacon',]})
print(df1)
print(df2)
In this case, the DataFrame would be split at the end of every 2 sets of unique entries in the df['Food'] column to create df1 and df2. Best case scenario would be a loop that creates a new DataFrame for every x unique entries. Given the lack of info I can find, I'm unfortunately struggling to write even good pseudocode for that.
CodePudding user response:
Possible solution is the following:
import pandas as pd
df = pd.DataFrame({'ID':[1,1,1,2,2,2,3,3,3,4,4,4],
'Period':[1,2,3,1,2,3,1,2,3,1,2,3,],
'Food':['Ham','Ham','Ham','Cheese','Cheese','Cheese','Egg','Egg','Egg','Bacon','Bacon','Bacon',]})
dfs = [y for x, y in df.groupby('Food', as_index=False)]
Separated dfs can be accessed by list index (see below) or using loop:
dfs[0]
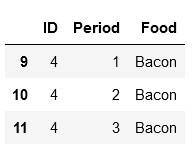
dfs[1]
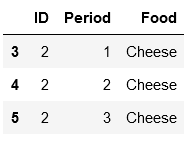
and etc.
CodePudding user response:
Let us try with factorize and groupby
n = 2
d = {x : y for x , y in df.groupby(df.Food.factorize()[0]//n)}
d[0]
Out[132]:
ID Period Food
0 1 1 Ham
1 1 2 Ham
2 1 3 Ham
3 2 1 Cheese
4 2 2 Cheese
5 2 3 Cheese
d[1]
Out[133]:
ID Period Food
6 3 1 Egg
7 3 2 Egg
8 3 3 Egg
9 4 1 Bacon
10 4 2 Bacon
11 4 3 Bacon
CodePudding user response:
We could use groupby ngroup floordiv to create groups; then use another groupby to separate:
out = [x for _, x in df.groupby(df.groupby('Food', sort=False).ngroup().floordiv(2))]
Output:
[ ID Period Food
0 1 1 Ham
1 1 2 Ham
2 1 3 Ham
3 2 1 Cheese
4 2 2 Cheese
5 2 3 Cheese,
ID Period Food
6 3 1 Egg
7 3 2 Egg
8 3 3 Egg
9 4 1 Bacon
10 4 2 Bacon
11 4 3 Bacon]
CodePudding user response:
From what I understand, this may help:
for x in df['ID'].unique():
print(df[df['ID']==x], '\n')
for x in df['Food'].unique():
print(df[df['Food']==x], '\n')