In my dataframe, I don't have the date column. I only have the sales for every month from Jan-2022 until Dec-2034. Below is the example of my dataframe:
import pandas as pd
data = [[6661, 'Mobile Phone', 43578, 5000, 78564, 52353], [6672, 'Play Station', 4475, 2546, 5757, 2352],
[6631, 'Personal Computer', 35347, 36376, 164577, 94584], [6600, 'Camera', 14365, 60785, 25436, 46747],
[6643, 'Lamp', 324355, 143255, 696954, 97823]]
ds = pd.DataFrame(data, columns = ['ID', 'Product', 'Sales_Jan-22', 'Sales_Feb-22', 'Sales_Mac-22', 'Sales_Apr-22'])
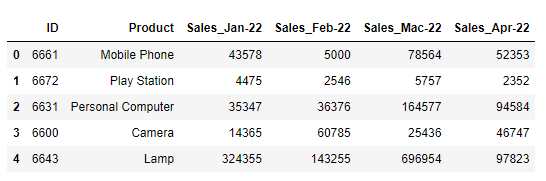
Since I have more than 10 monthly sales column, I want to loop the date after each of the month sales column. Below shows the sample of result that I want:
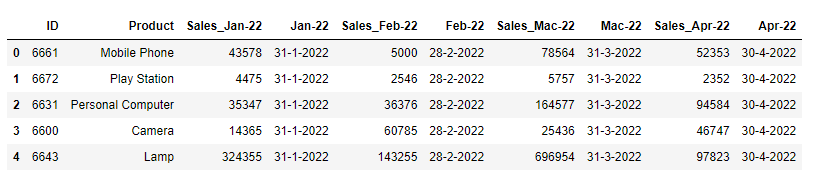
It's easy if the column is just less than 10. However, since the monthly would be from Jan-22 until Dec-2034 (quite a lot), is there any way to perform the loop and adding the date column beside each of the sales month?
CodePudding user response:
Why don't you create a Date column? It will be a lot easier to filter the data afterwards to get how many of a given product was sold in a month:
import pandas as pd
from datetime import datetime
data = [[6661, 'Mobile Phone', 43578, 5000, 78564, 52353], [6672, 'Play Station', 4475, 2546, 5757, 2352],
[6631, 'Personal Computer', 35347, 36376, 164577, 94584], [6600, 'Camera', 14365, 60785, 25436, 46747],
[6643, 'Lamp', 324355, 143255, 696954, 97823]]
ds = pd.DataFrame(data, columns = ['ID', 'Product', 'Sales_Jan-22', 'Sales_Feb-22', 'Sales_Mar-22', 'Sales_Apr-22'])
month_cols = ds.columns[ds.columns.str.contains('Sales')] # get all the months and years from the column names
m_y = [datetime.strptime(x[-6:], '%b-%y') for x in month_cols] # convert to datetime format
# Create a new dataframe with a 'Date' column
df = ds[['ID', 'Product']]
all_months = []
for i, d in enumerate(m_y):
df.loc[:, 'Date'] = d
df.loc[:, 'Sales'] = ds.loc[:, month_cols[i]]
all_months.append(df)
final_df = pd.concat(all_months).groupby(['Date', 'ID', 'Product']).sum()
final_df
ID Product Date Sales
0 6661 Mobile Phone 2022-04-01 52353
1 6672 Play Station 2022-04-01 2352
2 6631 Personal Computer 2022-04-01 94584
3 6600 Camera 2022-04-01 46747
4 6643 Lamp 2022-04-01 97823
0 6661 Mobile Phone 2022-04-01 52353
1 6672 Play Station 2022-04-01 2352
2 6631 Personal Computer 2022-04-01 94584
3 6600 Camera 2022-04-01 46747
4 6643 Lamp 2022-04-01 97823
0 6661 Mobile Phone 2022-04-01 52353
1 6672 Play Station 2022-04-01 2352
2 6631 Personal Computer 2022-04-01 94584
3 6600 Camera 2022-04-01 46747
4 6643 Lamp 2022-04-01 97823
0 6661 Mobile Phone 2022-04-01 52353
1 6672 Play Station 2022-04-01 2352
2 6631 Personal Computer 2022-04-01 94584
3 6600 Camera 2022-04-01 46747
4 6643 Lamp 2022-04-01 97823
CodePudding user response:
Updating the answer following @fhaney comment.
If all you want is to place a new column after each sales column, you can do:
def insert_col_after_sales(df, sales_col, new_col):
cols = df.columns.to_list()
i = df.columns.get_loc(sales_col)
cols.insert(i 1, new_col)
df[new_col] = ''
df = df.reindex(columns=cols)
df.loc[:, new_col] = datetime.strptime(new_col, '%b-%y')
return df
for i, d in enumerate(m_y):
sales_col = sales[i]
df = insert_col_after_sales(df, sales_col, d)
output:
| ID | Product | Sales_Jan-22 | Jan-22 | Sales_Feb-22 | Feb-22 | Sales_Mar-22 | Mar-22 | Sales_Apr-22 | Apr-22 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6661 | Mobile Phone | 43578 | 2022-01-01 | 5000 | 2022-02-01 | 78564 | 2022-03-01 | 52353 |
| 1 | 6672 | Play Station | 4475 | 2022-01-01 | 2546 | 2022-02-01 | 5757 | 2022-03-01 | 2352 |
| 2 | 6631 | Personal Computer | 35347 | 2022-01-01 | 36376 | 2022-02-01 | 164577 | 2022-03-01 | 94584 |
| 3 | 6600 | Camera | 14365 | 2022-01-01 | 60785 | 2022-02-01 | 25436 | 2022-03-01 | 46747 |
| 4 | 6643 | Lamp | 324355 | 2022-01-01 | 143255 | 2022-02-01 | 696954 | 2022-03-01 | 97823 |
CodePudding user response:
Another alternative (works only with corrected Mac-22 column name):
values = (pd.Series(pd.to_datetime(ds.columns[2:].str[-6:], format="%b-%y"))
.dt.to_period("M").dt.strftime("%d-%m-%Y"))
result = pd.concat(
[ds[ds.columns[:2]]] [
ds[[col]].assign(**{col[-6:]: value})
for col, value in zip(ds.columns[2:], values)
],
axis="columns"
)
Result:
ID Product Sales_Jan-22 Jan-22 Sales_Feb-22 \
0 6661 Mobile Phone 43578 31-01-2022 5000
1 6672 Play Station 4475 31-01-2022 2546
2 6631 Personal Computer 35347 31-01-2022 36376
3 6600 Camera 14365 31-01-2022 60785
4 6643 Lamp 324355 31-01-2022 143255
Feb-22 Sales_Mar-22 Mar-22 Sales_Apr-22 Apr-22
0 28-02-2022 78564 31-03-2022 52353 30-04-2022
1 28-02-2022 5757 31-03-2022 2352 30-04-2022
2 28-02-2022 164577 31-03-2022 94584 30-04-2022
3 28-02-2022 25436 31-03-2022 46747 30-04-2022
4 28-02-2022 696954 31-03-2022 97823 30-04-2022