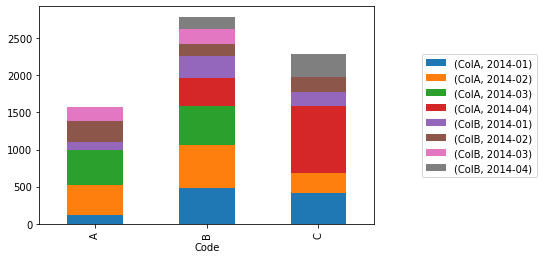import pandas as pd
import numpy as np
np.random.seed(365)
rows = 100
data = {'Month': np.random.choice(['2014-01', '2014-02', '2014-03', '2014-04'], size=rows),
'Code': np.random.choice(['A', 'B', 'C'], size=rows),
'ColA': np.random.randint(5, 125, size=rows),
'ColB': np.random.randint(0, 51, size=rows),}
df = pd.DataFrame(data)
df = df[((~((df.Code=='A')&(df.Month=='2014-04')))&(~((df.Code=='C')&(df.Month=='2014-03'))))]
dfg = df.groupby(['Code', 'Month']).sum()
For above. I wish to plot a stacked plot..
dfg.unstack(level=0).plot(kind='bar', stacked =True)
I wish to stack over 'Code' column. But, above is stacking over 'Month' Why?. How to better plot stacked plot with this?
CodePudding user response:
The index of the input dataframe is used by default as x-value in 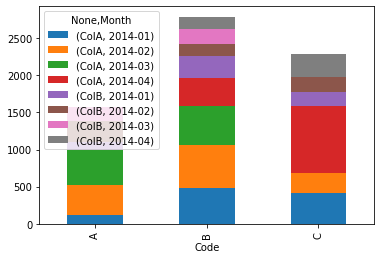
legend position:
ax = dfg.unstack(level=1).plot(kind='bar', stacked=True, legend=False)
ax.figure.legend(loc='center left', bbox_to_anchor=(1, 0.5))