I have an existing pandas dataframe, consisting of a country column and market column. I want to check if the countries are assigned to the correct markets. As such I created a dictionary where each country (key) is mapped to the correct markets (values) it can fall within. The structure of the dataframe is below:
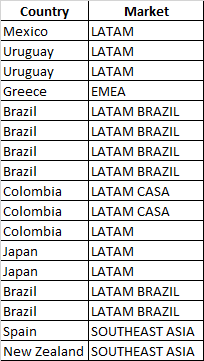
The structure of the dictionary is {'key':['Market 1', 'Market 2', 'Market 3']}. This is because each country has a couple of markets they could belong to.
I would like to write a function, which checks the values in the Country column and see if according to the dictionary, the current mapping is correct. So ideally, the desired output would be as follows:
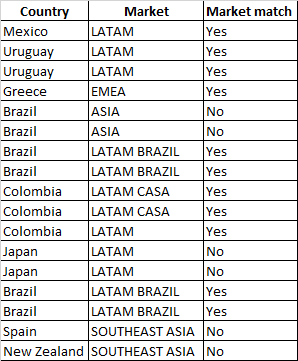
Is there a way to reference a dictionary across two columns in a function? To confirm, the keys are the country names, and the markets are the values.
I have included code required to make the dataframe:
data = {'Country': ['Mexico','Uruguay','Uruguay','Greece','Brazil','Brazil','Brazil','Brazil','Colombia','Colombia','Colombia','Japan','Japan','Brazil','Brazil','Spain','New Zealand'],
'Market': ['LATAM','LATAM','LATAM','EMEA','ASIA','ASIA','LATAM BRAZIL','LATAM BRAZIL','LATAM CASA','LATAM CASA','LATAM','LATAM','LATAM','LATAM BRAZIL','LATAM BRAZIL','SOUTHEAST ASIA','SOUTHEAST ASIA']
}
df = pd.DataFrame(data)
Thanks a lot.
CodePudding user response:
First idea is create tuples and match by Index.isin:
d = {'Colombia':['LATAM','LATAM CASA'], 'Brazil':['ASIA']}
tups = [(k, x) for k, v in d.items() for x in v]
df['Market Match'] = np.where(df.set_index(['Country','Market']).index.isin(tups),
'yes', 'no')
print (df)
Country Market Market Match
0 Mexico LATAM no
1 Uruguay LATAM no
2 Uruguay LATAM no
3 Greece EMEA no
4 Brazil ASIA yes
5 Brazil ASIA yes
6 Brazil LATAM BRAZIL no
7 Brazil LATAM BRAZIL no
8 Colombia LATAM CASA yes
9 Colombia LATAM CASA yes
10 Colombia LATAM yes
11 Japan LATAM no
12 Japan LATAM no
13 Brazil LATAM BRAZIL no
14 Brazil LATAM BRAZIL no
15 Spain SOUTHEAST ASIA no
16 New Zealand SOUTHEAST ASIA no
Or by left join in DataFrame.merge with indicator=True:
d = {'Colombia':['LATAM','LATAM CASA'], 'Brazil':['ASIA']}
df1 = pd.DataFrame([(k, x) for k, v in d.items() for x in v],
columns=['Country','Market']).drop_duplicates()
df['Market Match'] = np.where(df.merge(df1,indicator=True,how='left')['_merge'].eq('both'),
'yes', 'no')
CodePudding user response:
The following link might help you out in checking if specific strings (e.g. "Markets" are included in your dataframe).
Check if string contains substring
For example:
fullstring = "StackAbuse"
substring = "tack"
if substring in fullstring:
print("Found!")
else:
print("Not found!")
CodePudding user response:
df['MATCH'] = df.apply(lambda row: row['Market'] in your_dictionary[row['Country']], axis=1)