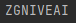
I am using Tesseract OCR trying to convert a preprocessed license plate image into text, but I have not had much success with some images which look very much OK. The tesseract setup can be seen in the function definition. I am running this on Google Colab. The input image is ZG NIVEA 1 below. I am not sure if I am using something wrong or if there is a better way to do this - the result I get form this particular image is A.

!sudo apt install -q tesseract-ocr
!pip install -q pytesseract
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
import cv2
import re
def pytesseract_image_to_string(img, oem=3, psm=7) -> str:
'''
oem - OCR Engine Mode
0 = Original Tesseract only.
1 = Neural nets LSTM only.
2 = Tesseract LSTM.
3 = Default, based on what is available.
psm - Page Segmentation Mode
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
11 = Sparse text. Find as much text as possible in no particular order.
12 = Sparse text with OSD.
13 = Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
'''
tess_string = pytesseract.image_to_string(img, config=f'--oem {oem} --psm {psm}')
regex_result = re.findall(r'[A-Z0-9]', tess_string) # filter only uppercase alphanumeric symbols
return ''.join(regex_result)
image = cv2.imread('nivea.png')
print(pytesseract_image_to_string(image))
Edit: The approach in the accepted answer works for the ZGNIVEA1 image, but not for others, e.g.  , is there a general "font size" that Tesseract OCR works with best, or is there a rule of thumb?
, is there a general "font size" that Tesseract OCR works with best, or is there a rule of thumb?
CodePudding user response:
by applying gaussian blur before OCR, I ended up with the correct output. Also, you may not need to use regex by adding -c tessedit_char_whitelist=ABC.. to your config string.
The code that produces correct output for me:
import cv2
import pytesseract
image = cv2.imread("images/tesseract.png")
config = '--oem 3 --psm 7 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ'
image = cv2.resize(image, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
image = cv2.GaussianBlur(image, (5, 5), 0)
string = pytesseract.image_to_string(image, config=config)
print(string)
Output: