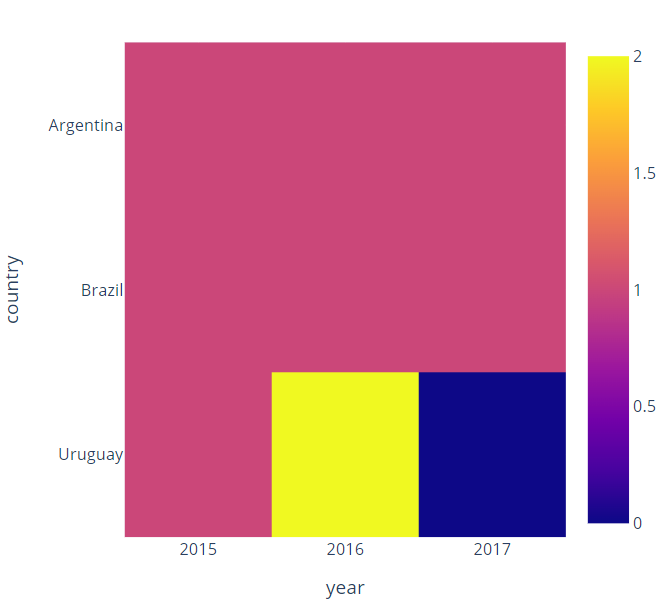
I am doing some volunteer work for a South American NGO that maps criminality in the continent. It is my first time using pandas and I would be most grateful if you could help me with the following scenario.
I have the following DataFrame:
df = pd.DataFrame({'country': ['Brazil', 'Argentina', 'Uruguay', 'Brazil', 'Argentina', 'Uruguay', 'Brazil', 'Argentina', 'Uruguay'],
'year': [2015, 2015, 2015, 2016, 2016, 2016, 2017, 2017, 2016],
'occurrence': ['murder', 'murder', 'rape', 'rape', 'arson', 'arson', 'murder', 'murder', 'arson']})
I would like to sum the crime occurrences per country per year and display the results using a plotly express heatmap in which the years would be mapped to the x axis, the countries to the y axis and the colours would show the number of occurrences.
Do you think you could help me transform the data and feed it into the appropriate plotly express heatmap function?
Thank you!
CodePudding user response:
You should first group your data by country and then by year and count number of crimes:
new_df = df.groupby(["country","year"])["occurrence"].count().reset_index()
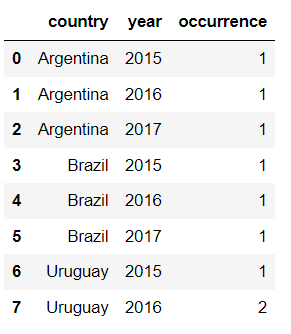
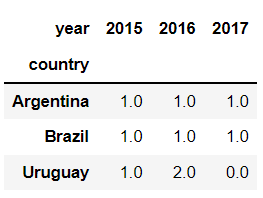
After that, you should change the structure of the data by pivoting the data according to your needs:
new_df = new_df.pivot(index='country', columns='year')['occurrence'].fillna(0)
Now, you can plot your heatmap:
import plotly.express as px
fig = px.imshow(new_df, x=new_df.columns, y=new_df.index)
fig.update_layout(width=500,height=500)
fig.show()