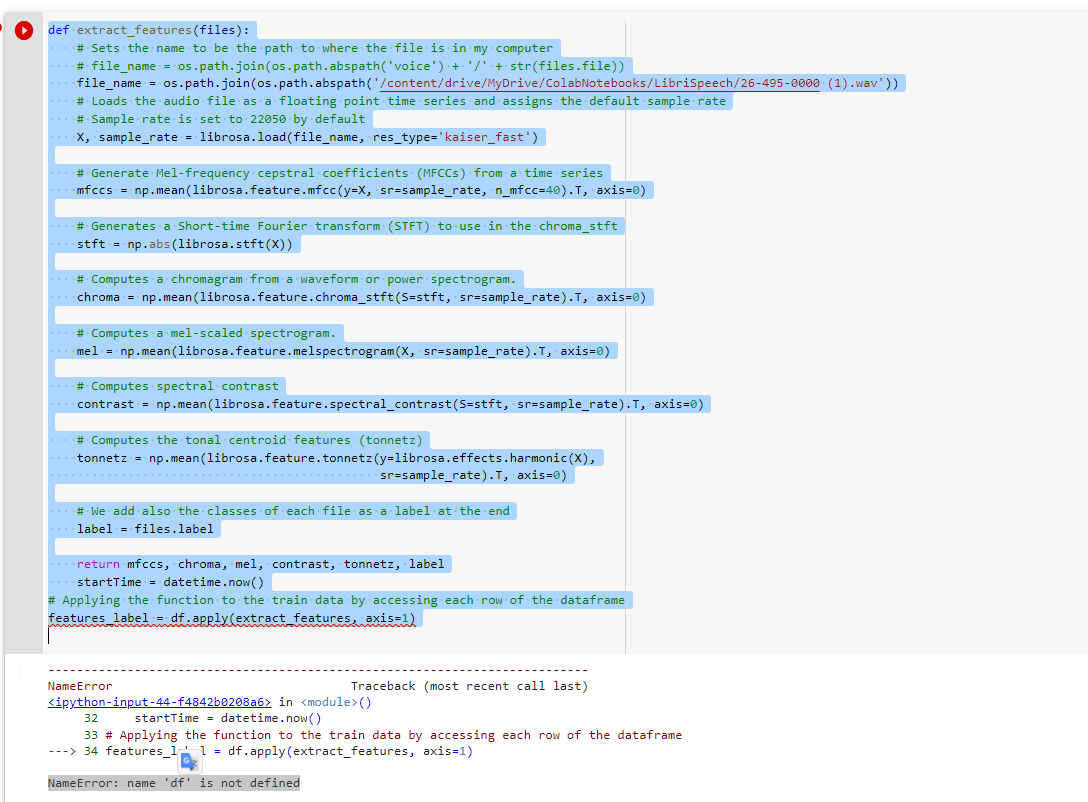
def extract_features(files):
# Sets the name to be the path to where the file is in my computer
# file_name = os.path.join(os.path.abspath('voice') '/' str(files.file))
file_name = os.path.join(os.path.abspath('/content/drive/MyDrive/ColabNotebooks/LibriSpeech/26-495-0000 (1).wav'))
# Loads the audio file as a floating point time series and assigns the default sample rate
# Sample rate is set to 22050 by default
X, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
# Generate Mel-frequency cepstral coefficients (MFCCs) from a time series
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
# Generates a Short-time Fourier transform (STFT) to use in the chroma_stft
stft = np.abs(librosa.stft(X))
# Computes a chromagram from a waveform or power spectrogram.
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
# Computes a mel-scaled spectrogram.
mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T, axis=0)
# Computes spectral contrast
contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=sample_rate).T, axis=0)
# Computes the tonal centroid features (tonnetz)
tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(X),
sr=sample_rate).T, axis=0)
# We add also the classes of each file as a label at the end
label = files.label
return mfccs, chroma, mel, contrast, tonnetz, label
startTime = datetime.now()
# Applying the function to the train data by accessing each row of the dataframe
features_label = df.apply(extract_features, axis=1)
CodePudding user response:
You need to first declare and define the dataframe, on which you want to apply this function. Then call the apply method on that particular dataframe.
For more information on correct usage of pandas.DataFrame.apply, check -- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html
CodePudding user response:
You have to read the data from CSV file. And assign it to df and then do df.apply.
import pandas as pd
df = pd.read_csv("CSV file path")