I'm working on a huge dataset of movies and I'm trying to get the IMDb ID of each movie from the IMDB website. I'm using selenium in Python. I checked, but inside the movie page you can't find the IMDB code. It is contained into the link of the page, which is in the address bar and I don't know how to scrape it. Are there any methods of doing this?
This is an example of the page:
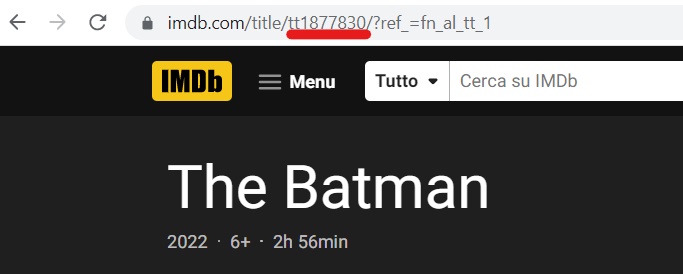
I need to get the underlined part of the url.
Does anyone know how to do it?
CodePudding user response:
If you want to fetch the title of movie url you need to first fetch the current_url and then using python split() function you can get the second last string.
currenturl=driver.current_url.split("/")[-2]
print(currenturl)
This will returned tt1877830
CodePudding user response:
Try driver.current_url
Reference: https://selenium-python.readthedocs.io/api.html
Also, worth noting that IMDB has an official API. You could look at that as well https://aws.amazon.com/marketplace/pp/prodview-bj74roaptgdpi?sr=0-1&ref_=beagle&applicationId=AWSMPContessa
CodePudding user response:
To extract the page url 9or a part of it i.e. the underlined part) e.g. tt1877830, you can extract the current_url and split it with respect to the / character and you can use either of the following solutions:
Using Positive Index:
driver.get('https://www.imdb.com/title/tt1877830/?ref_=fn_al_tt_1') WebDriverWait(driver, 20).until(EC.url_contains("title")) print(driver.current_url.split("/")[4])Console Output:
tt1877830Using Negative Index:
driver.get('https://www.imdb.com/title/tt1877830/?ref_=fn_al_tt_1') WebDriverWait(driver, 20).until(EC.url_contains("title")) print(driver.current_url.split("/")[-2])Console Output:
tt1877830Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC