I want to create a time series where I extract the time column from my data set and start the series from the earliest instance
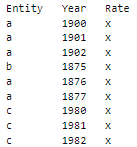
I have a dataset that looks something like this:
Entity Year Rate
a 1900 x
a 1901 x
a 1902 x
b 1875 x
a 1876 x
a 1877 x
c 1980 x
c 1981 x
c 1982 x
c 1983 x
I have divided the dataset into subsets filtered by entity. I want to create a timeseries for entity a starting at the year 1900. All I know to do is
tsA <- ts(subsetA, start = 1900, frequency = 1)
when creating the subset or the timeseries, is there a way to get R to recognize the "year" column and run the time series through the dates in the year column for that entity?
CodePudding user response:
Using the {zoo} packages you can get it done.
data <- data.frame(
year = sample(2000:2020, 20, replace = FALSE),
rate = runif(20)
)
data
#> year rate
#> 1 2001 0.93883378
#> 2 2018 0.01560548
#> 3 2013 0.16757567
#> 4 2012 0.98178756
#> 5 2000 0.83464269
#> 6 2007 0.54851239
#> 7 2008 0.52650996
#> 8 2011 0.34232266
#> 9 2014 0.83018549
#> 10 2010 0.43162665
#> 11 2017 0.53488659
#> 12 2009 0.31031984
#> 13 2004 0.37713368
#> 14 2016 0.14547139
#> 15 2003 0.58170074
#> 16 2005 0.81648560
#> 17 2019 0.12178940
#> 18 2015 0.33283621
#> 19 2006 0.61083482
#> 20 2002 0.07795245
# with the argument `order.by` the function order your timeseries,
# This argument can be a date, in case of timeseries with another frequency
data_ts <- zoo::zoo(data[ ,-1], order.by = data$year)
data_ts
#> 2000 2001 2002 2003 2004 2005 2006
#> 0.83464269 0.93883378 0.07795245 0.58170074 0.37713368 0.81648560 0.61083482
#> 2007 2008 2009 2010 2011 2012 2013
#> 0.54851239 0.52650996 0.31031984 0.43162665 0.34232266 0.98178756 0.16757567
#> 2014 2015 2016 2017 2018 2019
#> 0.83018549 0.33283621 0.14547139 0.53488659 0.01560548 0.12178940
Created on 2022-03-28 by the 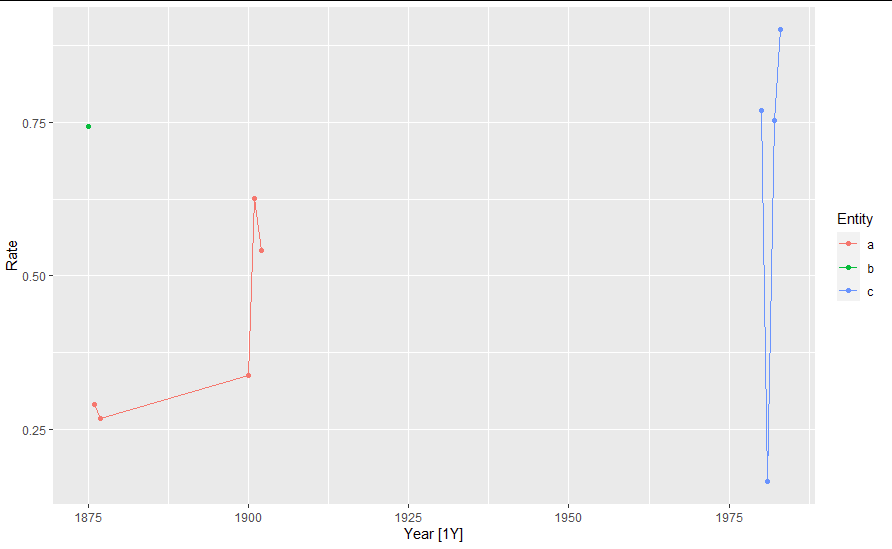
data:
df1 <- structure(list(Entity = c("a", "a", "a", "b", "a", "a", "c",
"c", "c", "c"), Year = c(1900L, 1901L, 1902L, 1875L, 1876L, 1877L,
1980L, 1981L, 1982L, 1983L), Rate = c(0.336955619277433, 0.626354965148494,
0.540716192685068, 0.743173609254882, 0.290504944045097, 0.266880671493709,
0.770237174350768, 0.164355911314487, 0.753349485108629, 0.900830976199359
)), row.names = c(NA, -10L), class = "data.frame")
CodePudding user response:
Suppose we have the data frame shown reproducibly in the Note at the end. Then we can read it into a zoo object and possibly to various other forms. The ts object will fill in empty years with NA but the zoo object can represent irregularly spaced series so it does not need to do that.
library(zoo)
z <- read.zoo(DF, index = 2, split = 1); z
# just part that starts at 1900
window(z, start = 1900)
# as a ts series
tt <- as.ts(z)
# as a wide data.frame
fortify.zoo(z)
# as a long data.frame
fortify.zoo(z, melt = TRUE)
# same but without NAs
na.omit(fortify.zoo(z, melt = TRUE))
# plot - omit facet=NULL to get separate panels
library(ggplot2)
autoplot(z, facet = NULL, geom = "point") geom_line()
# plot lines only without points
autoplot(z, facet = NULL)
# using data frames
DF1900 <- subset(DF, Year >= 1900)
split(DF1900, DF1900$Entity)
Note
Lines <- "Entity Year Rate
a 1900 x
a 1901 x
a 1902 x
b 1875 x
a 1876 x
a 1877 x
c 1980 x
c 1981 x
c 1982 x
c 1983 x"
DF <- read.table(text = Lines, header = TRUE)
DF$Rate <- 1:nrow(DF)