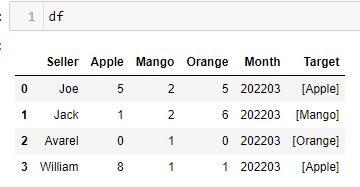
Hello all I have a simple df as shown above. Target column contains column names created with a lambda from other table
targetmain['Target']=targetmain.apply(lambda row: row[row == 1].index.tolist() , axis=1)
What I want to do is to create a new column based on Target column named "Primary", checking what is the target and the number matching the respective column. (eg. for Joe the column "Primary" should be 5, jack 2,avarel 0, william 8)
also if the brackets are an issue I can remove them as well.
CodePudding user response:
First remove lists by seelcting first value and then use lookup:
targetmain['Target'] = targetmain['Target'].str[0]
idx, cols = pd.factorize(targetmain['Target'])
df['Primary'] = targetmain.reindex(cols, axis=1).to_numpy()[np.arange(len(targetmain)), idx]
For old pandas versions use DataFrame.lookup:
targetmain['Target'] = targetmain['Target'].str[0]
targetmain['Primary'] = targetmain.lookup(targetmain.index, targetmain['Target'])
CodePudding user response:
Considering that the values in the column Target are strings :
def primaryCount(row):
row['Primary'] = row[row['Target']]
return row
targetmain = targetmain.apply(primaryCount, axis=1)
You may need to cast your Target values like @jezrael suggested with this beforehand :
targetmain['Target'] = targetmain['Target'].str[0]
EDIT : This solution could be simplified :
df['Primary'] = df.apply(lambda row: row[row['Target']], axis=1)