I'm really new to scrapping data and I am having trouble scrapping multiple pages. I'm trying to get the title of an episode as well as the rating for the episode.
I am only successful in getting the first page scrapped and then it won't work after that.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
url = 'https://www.imdb.com/title/tt0386676/episodes?season=1'
next_season = "//*[@id='load_next_episodes']"
browser = webdriver.Chrome()
browser.get(url)
for season in range(1,10):
i = 1
episodes = browser.find_elements_by_class_name('info')
for episode in episodes:
title = episode.find_element_by_xpath(f'//*[@id="episodes_content"]/div[2]/div[2]/div[{i}]/div[2]/strong/a').text
rating = episode.find_element_by_class_name('ipl-rating-star__rating').text
print(title, rating)
i = 1
browser.find_element_by_xpath(next_season).click()
browser.close()
My output looks like this:
Pilot 7.4
Diversity Day 8.2
Health Care 7.7
The Alliance 7.9
Basketball 8.3
Hot Girl 7.6
CodePudding user response:
You get the page details without clicking on season button as well.
You can first get all the season number from the dropdown box and then iterate.
You can create list and append the data in it and then can iterate at the end or can load into a dataframe and then export into CSV file.
Code:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
driver = webdriver.Chrome()
driver.get("https://www.imdb.com/title/tt0386676/episodes?season=1")
wait=WebDriverWait(driver,10)
selectSeason=wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, '#bySeason')))
select=Select(selectSeason)
allSeasons=[option.get_attribute('value') for option in select.options] #get all season numbers
print(allSeasons)
title=[]
ratings=[]
for season in allSeasons:
url="https://www.imdb.com/title/tt0386676/episodes?season={}".format(season)
print(url)
driver.get(url)
for e in wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, ".info"))):
title.append(e.find_element(By.CSS_SELECTOR, "a[itemprop='name']").text)
ratings.append(e.find_element(By.CSS_SELECTOR, ".ipl-rating-star.small .ipl-rating-star__rating").text)
for t , r in zip(title, ratings):
print(t " --- " r)
Output:
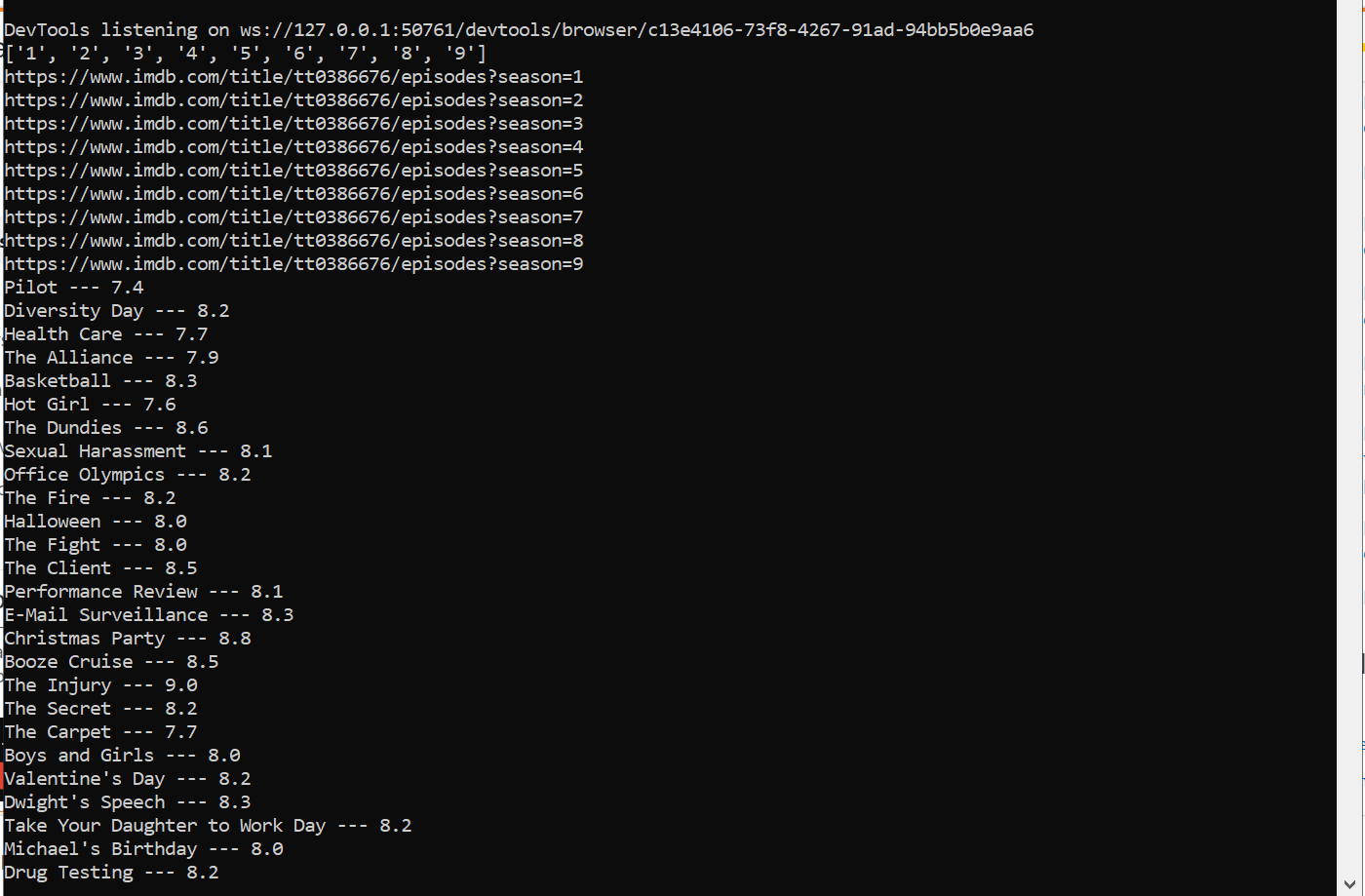
CodePudding user response:
The easy way is a manual wait at the top of the for loop. Dynamic waits are better practice. On the second iteration, your for loop may be failing to find the second page because it is loading.