Is there a way one can scrape data from multiple RSS feeds and store results?
I'm scraping data from multiple RSS feeds and storing them respectively in their CSVs in the worst way possible - Separate .py files for each feed to their CSVs and running all .py files in the folder.
I have multiple py files like this in a folder with only the url different. I'm not sure how to run them in a loop and store the results in their respective CSVs
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'anyRSSFeedLink.com'
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
output = []
for entry in soup.find_all('entry'):
item = {
'Title': entry.find('title', {'type': 'html'}).text,
'Pubdate': entry.find('published').text,
'Content': entry.find('content').text,
'Link': entry.find('link')['href']
}
output.append(item)
df = pd.DataFrame(output)
df.to_csv('results/results_feed01.csv', index=False)
How can I read from a CSV that has all the RSS feed links like this:
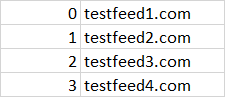
And run them in a single scraping file while storing in their respective result's CSVs that looks something like this?
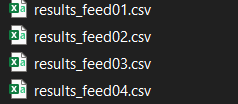
CodePudding user response:
Is there a way one can scrape data from multiple RSS feeds and store results?
Yes it is - Simply read your urls into a list or iterate directly over each line in your csv.
feeds = ['http://feeds.bbci.co.uk/news/rss.xml','http://www.cbn.com/cbnnews/us/feed/']
for url in feeds:
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'xml')
output = []
for entry in soup.find_all('item'):
item = {
'Title': entry.find('title').text,
'Pubdate': e.text if(e := entry.find('pubDate')) else None,
'Content': entry.find('description').text,
'Link': entry.find('link').text
}
output.append(item)
In each iteration you scrape the feed and save it to its csv, that e.g. could be named by domain, ...
df.to_csv(f'results_feed_{url.split("/")[2]}.csv', index=False)
or use a counter if you like:
for enum, url in enumerate(feeds):
...
df.to_csv(f'results_feed{enum}.csv', index=False)
Be aware - This will only work, if all feeds follows the same stucture, else you have to make some adjustments. You also should check if your elements you try to find are available before calling methods or properties:
'Pubdate': e.text if(e := entry.find('pubDate')) else None
Example
import requests
from bs4 import BeautifulSoup
import pandas as pd
feeds = ['http://feeds.bbci.co.uk/news/rss.xml','http://www.cbn.com/cbnnews/us/feed/']
for url in feeds:
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'xml')
output = []
for entry in soup.find_all('item'):
item = {
'Title': entry.find('title').text,
'Pubdate': e.text if(e := entry.find('pubDate')) else None,
'Content': entry.find('description').text,
'Link': entry.find('link').text
}
output.append(item)
df = pd.DataFrame(output)
df.to_csv(f'results_feed_{url.split("/")[2]}.csv', index=False)