I have a big matrix, like this:
df:
A A A B B ... (column names)
A 2 4 5 9 2
A 6 8 7 6 4
A 5 2 6 4 5
B 3 4 1 3 4
B 4 5 3 1 4
.
.
(row names)
I would like to merge the columns with same name, and findig the minimum value. At the end I would like to have a matrix like this:
df_min:
A B ... (column names)
A 2 2
A 6 4
A 2 4
B 1 3
B 3 1
.
.
(row names)
My intentions, afterwards (outside of the question), is to merge the rows as well. Desired outcome:
df_min:
A B ... (column names)
A 2 2
B 1 1
.
.
(row names)
I tried this:
df_min= df.groupby('df.columns, axis=1').agg(np.min)
But it didn't work, it removed some rows (for example, removing entirely row A)... EDIT: Apparently, it worked fine but I had two columns with different names but whitespace at the end of the name. These methods reorder the columns, which confused me.
A snipped of the dataframe:
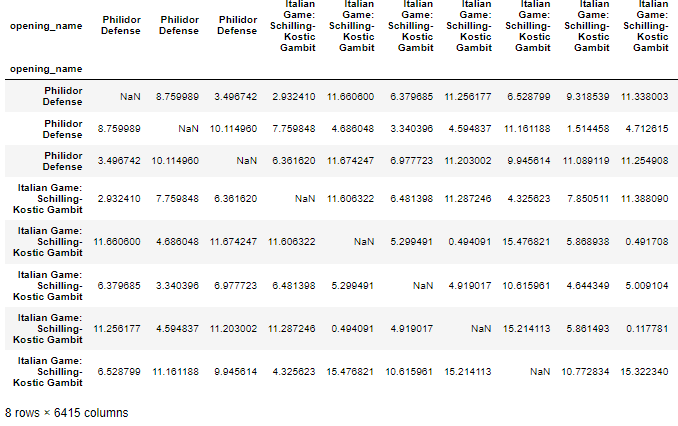
CodePudding user response:
Simply groupby on the level=0 for each axis:
df.groupby(level=0, axis=1).min()
output:
A B
A 2 2
A 6 4
A 2 4
B 1 3
B 3 1
both axes:
df.groupby(level=0, axis=1).min().groupby(level=0).min()
output:
A B
A 2 2
B 1 1
Alternatively, use a single groupby trough a stack/unstack:
df.stack().groupby(level=[0,1]).min().unstack()
output:
A B
A 2 2
B 1 1
CodePudding user response:
EDIT
numpy only based solution
I'm assuming that you have a list associating names to column indices, e.g. for the first code sample you provided something like
column_names = ['A', 'A', 'A', 'B', 'B']
and that your data type is single-precision floating point. In this scenario, you can do something like the following:
unique_column_names = list(dict.fromkeys(column_names)) # get unique column names preserving original order
df_min = np.empty((df.shape[0], len(unique_column_names), dtype=np.float32) # allocate output array
for i, column_name in enumerate(unique_column_names): # iterate over unique column names
column_indices = [id for id in range(df.shape[1]) if column_names[id] == column_name] # extract all column indices having the same name
tmp = df[:, column_indices] # extract columns named as column_name
df_min[:, i] = np.amin(tmp, axis=1)] # take min by row and save result
Then, if you want to repeat the process by row, assuming you have another list associating row indices and names named row_names
unique_row_names = list(dict.fromkeys(row_names)) # get unique row names preserving order
df_final = np.empty((len(unique_row_names), len(unique_column_names), dtype=np.float32) # allocate final output
for j, row_name in enumerate(unique_row_names): # iterate over unique row names
row_indices = [id for id in range(df.shape[0]) if row_names[id] == row_name] # extract rows having row_name
tmp = df_min[row_indices, :] # extract rows named as row_name from the column-reduced matrix
df_final[j, :] = np.amin(tmp, axis=0) # take min by column and save result
The column-name and row-name association list for the final output are unique_column_names and unique_row_names