I am applying federated averaging on my federated learning model. After running the model for thousands rounds the model still did not converged. How can I increase the number of epochs in training, and how it differs from the number of rounds? And how can I reach to convergence, since I tried to increase the number of rounds but it take long time to train (I am using Google Colab, and the execution time can not be more than 24 hours I also tried subscribed to Google Colab Pro to use the GPU but it did not work well)
The code and the training results are provided below
train_data = [train.create_tf_dataset_for_client(c).repeat(2).map(reshape_data)
.batch(batch_size=50,num_parallel_calls=50)
for c in train_client_ids]
iterative_process = tff.learning.build_federated_averaging_process(
model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.0001),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.9))
NUM_ROUNDS = 50000
state = iterative_process.initialize()
logdir = "/tmp/logs/scalars/training/"
summary_writer = tf.summary.create_file_writer(logdir)
with summary_writer.as_default():
for round_num in range(0, NUM_ROUNDS):
state, metrics = iterative_process.next(state, train_data)
if (round_num% 1000) == 0:
print('round {:2d}, metrics={}'.format(round_num, metrics))
for name, value in metrics['train'].items():
tf.summary.scalar(name, value, step=round_num)
And the output in shown in
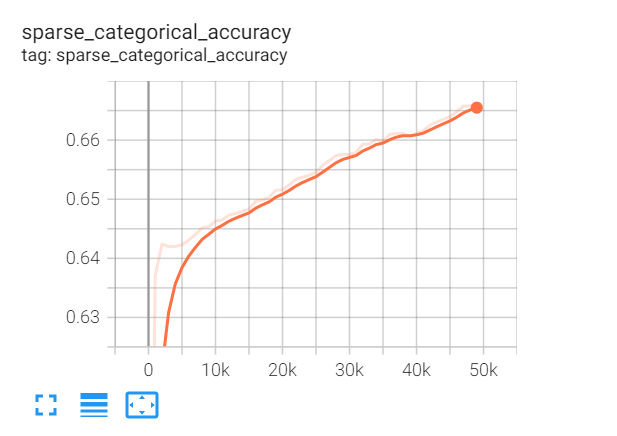
CodePudding user response:
See this tutorial for how to increase epochs (basically increase the number in .repeat()). The number of epochs is the number of iterations a client train on each batch. The number of rounds is the total number of federated computation.