Here is an example dataset found from google search close to my datasets in my environment
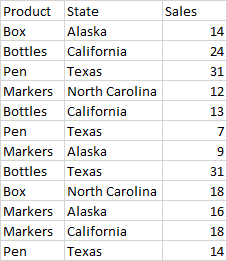
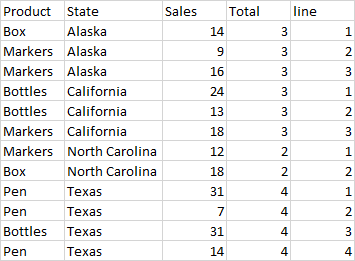
I'm trying to get output like this
import pandas as pd
import numpy as np
data = {'Product':['Box','Bottles','Pen','Markers','Bottles','Pen','Markers','Bottles','Box','Markers','Markers','Pen'],
'State':['Alaska','California','Texas','North Carolina','California','Texas','Alaska','Texas','North Carolina','Alaska','California','Texas'],
'Sales':[14,24,31,12,13,7,9,31,18,16,18,14]}
df=pd.DataFrame(data, columns=['Product','State','Sales'])
df1=df.sort_values('State')
#df1['Total']=df1.groupby('State').count()
df1['line']=df1.groupby('State').cumcount() 1
print(df1,index=False)
Commented out line throws this error
ValueError: Columns must be same length as key
Tried with size() it gives NaN for all rows
Hope someone points me to right direction Thanks in advance
CodePudding user response:
I think this should work for 'Total':
df1['Total']=df1.groupby('State')['Product'].transform(lambda x: x.count())
CodePudding user response:
Try this:
df = pd.DataFrame(data).sort_values("State")
grp = df.groupby("State")
df["Total"] = grp["State"].transform("size")
df["line"] = grp.cumcount() 1