The training accuracy and validation accuracy of my model is extremely high.
...
Epoch 4/5
457/457 [==============================] - 4s 8ms/step - loss: 0.0237 - accuracy: 0.9925 - val_loss: 0.0036 - val_accuracy: 0.9993
Epoch 5/5
457/457 [==============================] - 4s 8ms/step - loss: 0.0166 - accuracy: 0.9941 - val_loss: 0.0028 - val_accuracy: 0.9994
However, upon testing, the accuracy is atrocious:
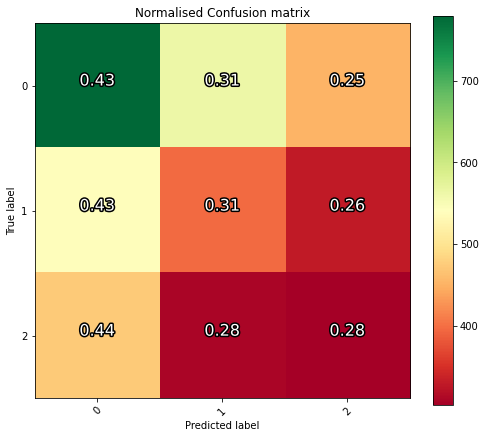
(for high accuracy there would be a green diagonal from top-left to bottom-right)
I am not sure why this is, given the high accuracy and low loss of both the training and validation set. If the model was overfitting, then either the validation loss or accuracy should be deviating from the training loss or accuracy, but it is not. Here are my data generators:
train_datagen = DataGenerator(
partition["train"],
labels,
batch_size=BATCH_SIZE,
**params
)
val_datagen = DataGenerator(
partition["val"],
labels,
batch_size=BATCH_SIZE,
**params
)
test_datagen = DataGenerator(
partition["test"],
labels,
batch_size=1,
**params
)
Note that since my data takes the form of a npy array on a .npy file, I followed 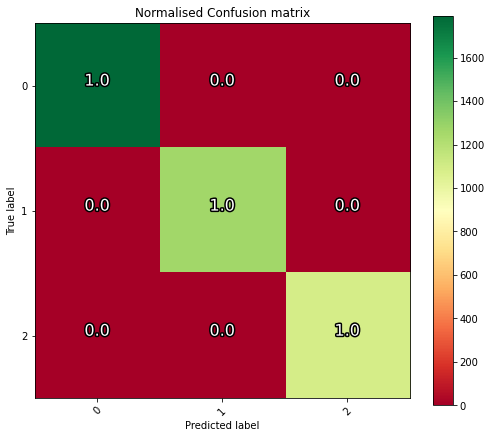
My neural net successfully reached >99% accuracy on the testing dataset, as was reflected in the training and validation sets. Only 1 wrong prediction was made out of 4144.
The problem was that I had shuffle turned on for the training dataset, so when comparing to the non-shuffled list of correct classes that was generated at the start, the results were completely random.