I am working on a query in SQL Server that is giving me a result set that looks something like this:
| ID | DaysInState | DaysInState2 | DaysInState3 | DaysInState4 |
|---|---|---|---|---|
| 1 | 2022-04-01 | 2022-04-07 | NULL | NULL |
| 2 | NULL | 2022-04-09 | NULL | NULL |
| 3 | 2022-04-11 | 2022-04-15 | NULL | 2022-04-18 |
| 4 | 2022-04-11 | NULL | NULL | 2022-04-18 |
I need to calculate the number of days that a given item spent in a given state. The challenge I am facing is 'looking ahead' in the row. Using row 1 as an example these would be the following values:
- DaysInState: 6 (
DATEDIFF(day, '2022-04-11', '2022-04-07')) - DaysInState2: 12 (
DATEDIFF(day, '2022-04-07', GETDATE())) - DaysInState3: NULL
- DaysInState4: NULL
The challenging part here is that for each column in each row, I have to look at all the columns to the right of the reference column to see if a date exists to use in DATEDIFF. If a date is not found to the right of the reference column then GETDATE() is used. The table below shows what the result set should look like:
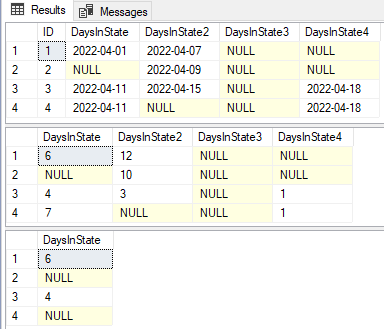
| ID | DaysInState | DaysInState2 | DaysInState3 | DaysInState4 |
|---|---|---|---|---|
| 1 | 6 | 12 | NULL | NULL |
| 2 | NULL | 10 | NULL | NULL |
| 3 | 4 | 3 | NULL | 1 |
| 4 | 7 | NULL | NULL | 1 |
I can write fairly convoluted CASE...WHEN statements for each column such that
SELECT
CASE
WHEN DaysInState IS NOT NULL AND DaysInState2 IS NOT NULL THEN DateDiff(day, DaysInState, DaysInState2)
WHEN DaysInState IS NOT NULL AND DaysInState2 IS NULL AND DaysInState3 IS NOT NULL THEN DateDiff(day, DaysInState, DaysInState3)
...
END
...
However this isn't very maintainable when states are added / removed. Is there a more dynamic approach to solving this problem that doesn't involve lengthy CASE statements or just generally a "better" approach that maybe I am not seeing?
CodePudding user response:
If it is possible to adjust the query generating your result set, I'd like to suggest a new approach. One advantage is that it can handle additional DayInState variables (5,6,7,...).
Rewrite your query so that your results have three columns: one for ID, one for "DayInState" number, and one for the date. That is, no NULL values returned. Union the result set with the distinct IDs, an exceedingly large "DayInState" number, and the result of GETDATE(). Then you can use DATEDIFF() with LAG() to look at the next dates.
Here's a working example in SQL Server using your data:
begin
declare @temp table (id int,state_num int,dt date)
insert into @temp values
(1,1,'2022-04-01'),
(1,2,'2022-04-07'),
(2,2,'2022-04-09'),
(3,1,'2022-04-11'),
(3,2,'2022-04-15'),
(3,3,'2022-04-18'),
(4,1,'2022-04-11'),
(4,4,'2022-04-18')
select t.id,t.state_num,DATEDIFF(day,t.dt,LAG(t.dt,1,GETDATE()) over(partition by t.id order by t.state_num desc))
from
(select * from @temp
union (select distinct id,999 as state_num, GETDATE() as dt from @temp) ) t
where t.state_num!=999
order by t.id,t.state_num
end
CodePudding user response:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[DateTest]') AND type in (N'U'))
DROP TABLE [dbo].[DateTest]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[DateTest](
[Id] [int] IDENTITY(1,1) NOT NULL,
[DaysInState] [date] NULL,
[DaysInState2] [date] NULL,
[DaysInState3] [date] NULL,
[DaysInState4] [date] NULL,
CONSTRAINT [PK_DateTest] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT INTO [dbo].[DateTest] ([DaysInState],[DaysInState2],[DaysInState3],[DaysInState4]) VALUES
('2022-04-01','2022-04-07',NULL,NULL),
(NULL,'2022-04-09',NULL,NULL),
('2022-04-11','2022-04-15',NULL,'2022-04-18'),
('2022-04-11',NULL,NULL,'2022-04-18');
GO
SELECT [ID],[DaysInState],[DaysInState2],[DaysInState3],[DaysInState4] FROM dbo.DateTest
Use nested ISNULL to check the next column or pass GETDATE(). Using the variable means you can alter the date if needed.
DECLARE @theDate date = GETDATE()
SELECT
[DaysInState] =DATEDIFF(day,[DaysInState], ISNULL([DaysInState2],ISNULL([DaysInState3],ISNULL([DaysInState4],@theDate))))
,[DaysInState2] =DATEDIFF(day,[DaysInState2],ISNULL([DaysInState3],ISNULL([DaysInState4],@theDate)))
,[DaysInState3] =DATEDIFF(day,[DaysInState3],ISNULL([DaysInState4],@theDate))
,[DaysInState4] =DATEDIFF(day,[DaysInState4],@theDate)
FROM dbo.DateTest
Your original query
SELECT
[DaysInState]=CASE
WHEN DaysInState IS NOT NULL AND DaysInState2 IS NOT NULL THEN DateDiff(day, DaysInState, DaysInState2)
WHEN DaysInState IS NOT NULL AND DaysInState2 IS NULL AND DaysInState3 IS NOT NULL THEN DateDiff(day, DaysInState, DaysInState3)
END
FROM dbo.DateTest
CodePudding user response:
The COALESCE function allows multiple parameters, evaluating them from left to right, returning the first non-null value, eliminating the need for nesting:
Daysinstate1=
datediff(day,
Daysinstate1,
Coalesce(daysinstate2
,Daysinstate3
,Daysinstate4
,Getdate())
)